In m_start, hartid:0 HTIF is available! (Emulated) memory size: 2048 MB Enter supervisor mode... Application: obj/app_print_backtrace Application program entry point (virtual address): 0x0000000081000072 Switching to user mode... back trace the user app **in** the following: f8 f7 f6 f5 f4 f3 f2 User exit with code:0. System is shutting down with exit code 0.
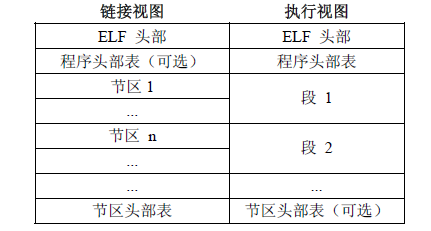
通过用户栈找到函数的返回地址后,需要将虚拟地址转换为源程序中的符号。这一点,读者需要了解ELF文件中的符号节(.symtab section),以及字符串节(.strtab section)的相关知识,了解这两个节(section)里存储的内容以及存储的格式等内容。对ELF的这两个节,网上有大量的介绍,例如这里,或阅读Linux Man Page。
1 /\* 2 \* Below is the given application for lab1_challenge2 (same as lab1_2). 3 \* This app attempts to issue M-mode instruction in U-mode, and consequently raises an exception. 4 \*/ 5 6 #include "user_lib.h" 7 #include "util/types.h" 8 9 **int** **main**(**void**) { 10 printu("Going to hack the system by running privilege instructions.\\n"); 11 // we are now in U(user)-mode, but the "csrw" instruction requires M-mode privilege. 12 // Attempting to execute such instruction will raise illegal instruction exception. 13 asm **volatile**("csrw sscratch, 0"); 14 exit(0); 15 } 16
In m_start, hartid:0 HTIF is available! (Emulated) memory size: 2048 MB Enter supervisor mode... Application: obj/app_errorline Application program entry point (virtual address): 0x0000000081000000 Switch to user mode... Going to hack the system by running privilege instructions. Runtime error at user/app_errorline.c:13 asm volatile("csrw sscratch, 0"); Illegal instruction! System is shutting down with exit code -1.
// code file struct, including directory index and file name char pointer typedef struct { uint64 dir; char *file; } code_file; // address-line number-file name table typedef struct { uint64 addr, line, file; } addr_line;
// the extremely simple definition of process, used for begining labs of PKE typedef struct process { // pointing to the stack used in trap handling. uint64 kstack; // trapframe storing the context of a (User mode) process. trapframe* trapframe; char *debugline; char **dir; code_file *file; addr_line *line; int line_ind; }process;
int main(void) { printu("Going to hack the system by running privilege instructions.\n");
// we are now in U(user)-mode, but the "csrw" instruction requires M-mode privilege. // Attempting to execute such instruction will raise illegal instruction exception. asm volatile("csrw sscratch, 0"); exit(0); }
1/\* 2 \* The application of lab2_4. 3 \* Based on application of lab2_3. 4 \*/ 5 6#include "user_lib.h" 7#include "util/types.h" 8 9// 10// compute the summation of an arithmetic sequence. for a given "n", compute 11// result = n + (n-1) + (n-2) + ... + 0 12// sum_sequence() calls itself recursively till 0. The recursive call, however, 13// may consume more memory (from stack) than a physical 4KB page, leading to a page fault. 14// PKE kernel needs to improved to handle such page fault by expanding the stack. 15// 16uint64 **sum_sequence**(uint64 n, **int** \*p) { 17 **if** (n == 0) 18 **return** 0; 19 **else** 20 **return** \*p=sum_sequence( n-1, p+1 ) + n; 21} 22 23**int** **main**(**void**) { 24 // FIRST, we need a large enough "n" to trigger pagefaults in the user stack 25 uint64 n = 1024; 26 27 // alloc a page size array(int) to store the result of every step 28 // the max limit of the number is 4kB/4 = 1024 29 30 // SECOND, we use array out of bound to trigger pagefaults in an invalid address 31 **int** \*ans = (**int** \*)naive_malloc(); 32 33 printu("Summation of an arithmetic sequence from 0 to %ld is: %ld \\n", n, sum_sequence(n+1, ans) ); 34 35 exit(0); 36}
In m_start, hartid:0 HTIF is available! (Emulated) memory size: 2048 MB Enter supervisor mode... PKE kernel start 0x0000000080000000, PKE kernel end: 0x000000008000e000, PKE kernel size: 0x000000000000e000 . free physical memory address: [0x000000008000e000, 0x0000000087ffffff] kernel memory manager is initializing ... KERN_BASE 0x0000000080000000 physical address of _etext is: 0x0000000080004000 kernel page table is on User application is loading. user frame 0x0000000087fbc000, user stack 0x000000007ffff000, user kstack 0x0000000087fbb000 Application: ./obj/app_sum_sequence Application program entry point (virtual address): 0x00000000000100da Switching to user mode... handle_page_fault: 000000007fffdff8 handle_page_fault: 000000007fffcff8 handle_page_fault: 000000007fffbff8 handle_page_fault: 000000007fffaff8 handle_page_fault: 000000007fff9ff8 handle_page_fault: 000000007fff8ff8 handle_page_fault: 000000007fff7ff8 handle_page_fault: 000000007fff6ff8 handle_page_fault: 0000000000401000 this address is not available! System is shutting down with exit code -1.
In m_start, hartid:0 HTIF is available! (Emulated) memory size: 2048 MB Enter supervisor mode... PKE kernel start 0x0000000080000000, PKE kernel end: 0x0000000080008000, PKE kernel size: 0x0000000000008000 . free physical memory address: [0x0000000080008000, 0x0000000087ffffff] kernel memory manager is initializing ... KERN_BASE 0x0000000080000000 physical address of _etext is: 0x0000000080005000 kernel page table is on User application is loading. user frame 0x0000000087fbc000, user stack 0x000000007ffff000, user kstack 0x0000000087fbb000 Application: obj/app_singlepageheap Application program entry point (virtual address): 0x00000000000100b0 Switch to user mode... hello world. User exit with code:0. System is shutting down with exit code 0.
In m_start, hartid:0 HTIF is available! (Emulated) memory size: 2048 MB Enter supervisor mode... PKE kernel start 0x0000000080000000, PKE kernel end: 0x0000000080009000, PKE kernel size: 0x0000000000009000 . free physical memory address: [0x0000000080009000, 0x0000000087ffffff] kernel memory manager is initializing ... KERN_BASE 0x0000000080000000 physical address of _etext is: 0x0000000080005000 kernel page table is on Switch to user mode... **in** alloc_proc. user frame 0x0000000087fbc000, user stack 0x000000007ffff000, user kstack 0x0000000087fbb000 User application is loading. Application: obj/app_wait CODE_SEGMENT added at mapped info offset:3 DATA_SEGMENT added at mapped info offset:4 Application program entry point (virtual address): 0x00000000000100b0 going to insert process 0 to ready queue. going to schedule process 0 to run. User call fork. will fork a child from parent 0. **in** alloc_proc. user frame 0x0000000087fae000, user stack 0x000000007ffff000, user kstack 0x0000000087fad000 do_fork map code segment at pa:0000000087fb2000 of parent to child at va:0000000000010000. going to insert process 1 to ready queue. going to schedule process 1 to run. User call fork. will fork a child from parent 1. **in** alloc_proc. user frame 0x0000000087fa1000, user stack 0x000000007ffff000, user kstack 0x0000000087fa0000 do_fork map code segment at pa:0000000087fb2000 of parent to child at va:0000000000010000. going to insert process 2 to ready queue. going to schedule process 2 to run. Grandchild process end, flag = 2. User exit with code:0. going to insert process 1 to ready queue. going to schedule process 1 to run. Child process end, flag = 1. User exit with code:0. going to insert process 0 to ready queue. going to schedule process 0 to run. Parent process end, flag = 0. User exit with code:0. no more ready processes, system shutdown now. System is shutting down with exit code 0.
In m_start, hartid:0 HTIF is available! (Emulated) memory size: 2048 MB Enter supervisor mode... PKE kernel start 0x0000000080000000, PKE kernel end: 0x0000000080009000, PKE kernel size: 0x0000000000009000 . free physical memory address: [0x0000000080009000, 0x0000000087ffffff] kernel memory manager is initializing ... KERN_BASE 0x0000000080000000 physical address of _etext is: 0x0000000080005000 kernel page table is on Switch to user mode... **in** alloc_proc. user frame 0x0000000087fbc000, user stack 0x000000007ffff000, user kstack 0x0000000087fbb000 User application is loading. Application: obj/app_semaphore CODE_SEGMENT added at mapped info offset:3 DATA_SEGMENT added at mapped info offset:4 Application program entry point (virtual address): 0x00000000000100b0 going to insert process 0 to ready queue. going to schedule process 0 to run. User call fork. will fork a child from parent 0. **in** alloc_proc. user frame 0x0000000087fae000, user stack 0x000000007ffff000, user kstack 0x0000000087fad000 do_fork map code segment at pa:0000000087fb2000 of parent to child at va:0000000000010000. going to insert process 1 to ready queue. Parent print 0 going to schedule process 1 to run. User call fork. will fork a child from parent 1. **in** alloc_proc. user frame 0x0000000087fa2000, user stack 0x000000007ffff000, user kstack 0x0000000087fa1000 do_fork map code segment at pa:0000000087fb2000 of parent to child at va:0000000000010000. going to insert process 2 to ready queue. Child0 print 0 going to schedule process 2 to run. Child1 print 0 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 1 going to insert process 1 to ready queue. going to schedule process 1 to run. Child0 print 1 going to insert process 2 to ready queue. going to schedule process 2 to run. Child1 print 1 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 2 going to insert process 1 to ready queue. going to schedule process 1 to run. Child0 print 2 going to insert process 2 to ready queue. going to schedule process 2 to run. Child1 print 2 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 3 going to insert process 1 to ready queue. going to schedule process 1 to run. Child0 print 3 going to insert process 2 to ready queue. going to schedule process 2 to run. Child1 print 3 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 4 going to insert process 1 to ready queue. going to schedule process 1 to run. Child0 print 4 going to insert process 2 to ready queue. going to schedule process 2 to run. Child1 print 4 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 5 going to insert process 1 to ready queue. going to schedule process 1 to run. Child0 print 5 going to insert process 2 to ready queue. going to schedule process 2 to run. Child1 print 5 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 6 going to insert process 1 to ready queue. going to schedule process 1 to run. Child0 print 6 going to insert process 2 to ready queue. going to schedule process 2 to run. Child1 print 6 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 7 going to insert process 1 to ready queue. going to schedule process 1 to run. Child0 print 7 going to insert process 2 to ready queue. going to schedule process 2 to run. Child1 print 7 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 8 going to insert process 1 to ready queue. going to schedule process 1 to run. Child0 print 8 going to insert process 2 to ready queue. going to schedule process 2 to run. Child1 print 8 going to insert process 0 to ready queue. going to schedule process 0 to run. Parent print 9 going to insert process 1 to ready queue. User exit with code:0. going to schedule process 1 to run. Child0 print 9 going to insert process 2 to ready queue. User exit with code:0. going to schedule process 2 to run. Child1 print 9 User exit with code:0. no more ready processes, system shutdown now. System is shutting down with exit code 0.