
跟着黑马程序员学习的学习记录!!!
前端
浏览器请求一个页面,前端服务器传给浏览器前端代码,浏览器解析前端代码然后向后端服务器请求数据。后端服务器还会向数据库请求数据。
html和css
1). 网页有哪些部分组成 ?
文字、图片、音频、视频、超链接、表格等等。
2). 我们看到的网页,背后的本质是什么 ?
程序员写的前端代码 (备注:在前后端分离的开发模式中,)
3). 前端的代码是如何转换成用户眼中的网页的 ?
通过浏览器转化(解析和渲染)成用户看到的网页,浏览器中对代码进行解析和渲染的部分,称为 浏览器内核。
但是呢,需要大家注意的是,不同的浏览器,内核不同,对于相同的前端代码解析的效果也会存在差异。 那这就会造成一个问题,同一段前端程序,不同浏览器展示出来的效果是不一样的,这个用户体验就很差了。而我们想达到的效果则是,即使用户使用的是不同的浏览器,解析同一段前端代码,最终展示出来的效果都是相同的。
要想达成这样一个目标,我们就需要定义一个统一的标准,然后让各大浏览器厂商都参照这个标准来实现即可。 而这套标准呢,其实早都已经定义好了,那就是我们接下来,要介绍的web标准。
Web标准也称为网页标准,由一系列的标准组成,大部分由W3C( World Wide Web Consortium,万维网联盟)负责制定。由三个组成部分:
HTML:负责网页的结构(页面元素和内容)。
CSS:负责网页的表现(页面元素的外观、位置等页面样式,如:颜色、大小等)。
JavaScript:负责网页的行为(交互效果)。
什么是HTML ?
**HTML: **HyperText Markup Language,超文本标记语言。
超文本:超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片、音频、视频等内容。除了文字还可以定义别的形式的内容。
标记语言:由标签构成的语言
- HTML标签都是预定义好的。例如:使用
<h1>标签展示标题,使用<a>展示超链接,使用<img>展示图片,<video>展示视频。- HTML代码直接在浏览器中运行,HTML标签由浏览器解析。
什么是CSS ?
CSS: Cascading Style Sheet,层叠样式表,用于控制页面的样式(表现)。
快速入门
HTML页面的基础结构标签,必须得有一个html和其从属的head和body,这是最基础的结构,缺一不可。
1 | <html> |
<title>中定义标题显示在浏览器的标题位置,<body>中定义的内容会呈现在浏览器的内容区域。下面是一个例子:
1 | <html> |
HTML文件以.html结尾。所有的标签都通过开始标签和结束标签括住。标签之间可以有嵌套和包括。如果没有被标签括起来的元素,就以普通文本的形式存在。
HTML中的标签特点
- HTML标签不区分大小写
- HTML标签的属性值,采用单引号、双引号都可以
- HTML语法相对比较松散 (建议大家编写HTML标签的时候尽量严谨一些)
基础标签
1). 图片标签 img
1 | A. 图片标签: <img> |
2). 标题标签 h 系列
1 | A. 标题标签: <h1> - <h6> |
3). 水平分页线标签 <hr>
4).没有语义的布局标签,宽度和高度默认由内容撑开。<span>
5). 超链接a标签
- 标签: <a href=”…” target=”…”>央视网
</a> - 属性:
- href: 指定资源访问的url
- target: 指定在何处打开资源链接
- _self: 默认值,在当前页面打开
- _blank: 在空白页面打开
6). 视频、音频标签
视频标签: <video>
- 属性:
- src: 规定视频的url
- controls: 显示播放控件
- width: 播放器的宽度
- height: 播放器的高度
- 属性:
音频标签: <audio>
- 属性:
- src: 规定音频的url
- controls: 显示播放控件
- 属性:
7). 段落标签
换行标签: <br>
- 注意: 在HTML页面中,我们在编辑器中通过回车实现的换行, 仅仅在文本编辑器中会看到换行效果, 浏览器是不会解析的, HTML中换行需要通过br标签
段落标签: <p>
- 如: <p> 这是一个段落 </p>
8). 文本格式标签
| 效果 | 标签 | 标签(强调) |
|---|---|---|
| 加粗 | b | strong |
| 倾斜 | i | em |
| 下划线 | u | ins |
| 删除线 | s | del |
前面的标签 b、i、u、s 就仅仅是实现加粗、倾斜、下划线、删除线的效果,是没有强调语义的。 而后面的strong、em、ins、del在实现加粗、倾斜、下划线、删除线的效果的同时,还带有强调语义。
9). 占位符
注意事项:
在HTML页面中无论输入了多少个空格, 最多只会显示一个。 可以使用空格占位符( ;)来生成空格,如果需要多个空格,就使用多次占位符。
那在HTML中,除了空格占位符以外,还有一些其他的占位符(了解, 只需要知道空格的占位符写法即可),如下:
显示结果 描述 占位符 空格 < 小于号 < > 大于号 > & 和号 & “ 引号 " ‘ 撇号 '
10). 布局标签:看下面的样式部分
11). 表格标签:
<table> : 用于定义整个表格, 可以包裹多个 <tr>, 常用属性如下:
- border:规定表格边框的宽度
- width:规定表格的宽度
- cellspacing: 规定单元之间的空间
<tr> : 表格的行,可以包裹多个 <td>
<td> : 表格单元格(普通),可以包裹内容 , 如果是表头单元格,可以替换为 <th>
12). 表单标签
- 表单场景: 表单就是在网页中负责数据采集功能的,如:注册、登录的表单。
- 表单标签: <form>
- 表单属性:
- action: 规定表单提交时,向何处发送表单数据,表单提交的URL。
- method: 规定用于发送表单数据的方式,常见为: GET、POST。
- GET:表单数据是拼接在url后面的, 如: xxxxxxxxxxx?username=Tom&age=12,url中能携带的表单数据大小是有限制的。
- POST: 表单数据是在请求体(消息体)中携带的,大小没有限制。
在一个表单中,可以存在很多的表单项,而虽然表单项的形式各式各样,但是表单项的标签其实就只有三个,分别是:
<input>: 表单项 , 通过type属性控制输入形式。
type取值 描述 text 默认值,定义单行的输入字段 password 定义密码字段 radio 定义单选按钮 checkbox 定义复选框 file 定义文件上传按钮 date/time/datetime-local 定义日期/时间/日期时间 number 定义数字输入框 email 定义邮件输入框 hidden 定义隐藏域 submit / reset / button 定义提交按钮 / 重置按钮 / 可点击按钮 <select>: 定义下拉列表, <option> 定义列表项
<textarea>: 文本域
创建一个新的表单项的html文件,具体内容如下:
1 |
|
基础样式
具体有3种引入方式,语法如下表格所示:
| 名称 | 语法描述 | 示例 |
|---|---|---|
| 行内样式 | 在标签内使用style属性,属性值是css属性键值对 | <h1 style=”xxx:xxx;”>中国新闻网</h1> |
| 内嵌样式 | 定义<style>标签,在标签内部定义css样式 | <style> h1 {…} </style> |
| 外联样式 | 定义<link>标签,通过href属性引入外部css文件 | <link rel=”stylesheet” href=”css/news.css”> |
对于上述3种引入方式,企业开发的使用情况如下:
- 内联样式会出现大量的代码冗余,不方便后期的维护,所以不常用。
- 内部样式,通过定义css选择器,让样式作用于当前页面的指定的标签上。
- 外部样式,html和css实现了完全的分离,企业开发常用方式。
颜色表示
在前端程序开发中,颜色的表示方式常见的有如下三种:
| 表示方式 | 表示含义 | 取值 |
|---|---|---|
| 关键字 | 预定义的颜色名 | red、green、blue… |
| rgb表示法 | 红绿蓝三原色,每项取值范围:0-255 | rgb(0,0,0)、rgb(255,255,255)、rgb(255,0,0) |
| 十六进制表示法 | #开头,将数字转换成十六进制表示 | #000000、#ff0000、#cccccc,简写:#000、#ccc |
CSS选择器
顾名思义:选择器是选取需设置样式的元素(标签),但是我们根据业务场景不同,选择的标签的需求也是多种多样的,所以选择器有很多种,因为我们是做后台开发的,所以对于css选择器,我们只学习最基本的3种。
选择器通用语法如下:
1 | 选择器名 { |
我们需要学习的3种选择器是元素选择器,id选择器,class选择器,语法以及作用如下:
1.元素(标签)选择器:
- 选择器的名字必须是标签的名字
- 作用:选择器中的样式会作用于所有同名的标签上
1 | 元素名称 { |
例子如下:
1 | div{ |
2.id选择器:
- 选择器的名字前面需要加上#
- 作用:选择器中的样式会作用于指定id的标签上,而且有且只有一个标签(由于id是唯一的)
1 | #id属性值 { |
例子如下:
1 | #did { |
3.类选择器:
- 选择器的名字前面需要加上 .
- 作用:选择器中的样式会作用于所有class的属性值和该名字一样的标签上,可以是多个
1 | .class属性值 { |
例子如下:
1 | .cls{ |
优先级:id选择器 类选择器 元素选择器
还有一些css的属性介绍:
1 | p { |
css除了控制属性,还可以控制页面布局:每个页面的元素都可以看成一个盒子。
盒子:页面中所有的元素(标签),都可以看做是一个 盒子,由盒子将页面中的元素包含在一个矩形区域内,通过盒子的视角更方便的进行页面布局
盒子模型组成:内容区域(content)、内边距区域(padding)、边框区域(border)、外边距区域(margin)

布局标签
布局标签:实际开发网页中,会大量频繁的使用 div 和 span 这两个没有语义的布局标签。
标签:
特点:
div标签:
一行只显示一个(独占一行)
宽度默认是父元素的宽度,高度默认由内容撑开
可以设置宽高(width、height)
span标签:
一行可以显示多个
宽度和高度默认由内容撑开
不可以设置宽高(width、height)
然后基于布局标签可以给布局标签写一个css来控制布局:
1
2
3
4
5
6
7
8
9
10
11div {
width: 200px; /* 宽度 */
height: 200px; /* 高度 */
box-sizing: border-box; /* 指定width height为盒子的高宽(内容+padding+border) */
background-color: aquamarine; /* 背景色 */
padding: 20px 20px 20px 20px; /* 内边距, 上 右 下 左 , 边距都一行, 可以简写: padding: 20px;*/
border: 10px solid red; /* 边框, 宽度 线条类型 颜色 */
margin: 30px 30px 30px 30px; /* 外边距, 上 右 下 左 , 边距都一行, 可以简写: margin: 30px; */
/*margin: 0 auto;*/
}JavaScript
引入方式
同样,js代码也是书写在html中的,那么html中如何引入js代码呢?主要通过下面的2种引入方式:
第一种方式:内部脚本,将JS代码定义在HTML页面中
- JavaScript代码必须位于<script></script>标签之间
- 在HTML文档中,可以在任意地方,放置任意数量的<script>
- 一般会把脚本置于<body>元素的底部,可改善显示速度
例子:
1
2
3<script>
alert("Hello JavaScript")
</script>第二种方式:外部脚本将, JS代码定义在外部 JS文件中,然后引入到 HTML页面中
- 外部JS文件中,只包含JS代码,不包含<script>标签
- 引入外部js的<script>标签,必须是双标签
例子:
1
<script src="js/demo.js"></script>
注意:demo.js中只有js代码,没有<script>标签
还有这个标签不能自闭合
基础语法
书写语法
掌握了js的引入方式,那么接下来我们需要学习js的书写了,首先需要掌握的是js的书写语法,语法规则如下:
区分大小写:与 Java 一样,变量名、函数名以及其他一切东西都是区分大小写的
每行结尾的分号可有可无
大括号表示代码块
注释:
单行注释:// 注释内容
多行注释:/* 注释内容 */
我们需要借助js中3钟输出语句,来演示书写语法
api 描述 window.alert() 警告框 document.write() 在HTML 输出内容 console.log() 写入浏览器控制台 变量
书写语法会了,变量是一门编程语言比不可少的,所以接下来我们需要学习js中变量的声明,在js中,变量的声明和java中还是不同的。首先js中主要通过如下3个关键字来声明变量的:
关键字 解释 var 早期ECMAScript5中用于变量声明的关键字 let ECMAScript6中新增的用于变量声明的关键字,相比较var,let只在代码块内生效 const 声明常量的,常量一旦声明,不能修改 在js中声明变量还需要注意如下几点:
- JavaScript 是一门弱类型语言,变量可以存放不同类型的值 。
- 变量名需要遵循如下规则:
- 组成字符可以是任何字母、数字、下划线(_)或美元符号($)
- 数字不能开头
- 建议使用驼峰命名
var可以重复定义,但是let不可以。
数据类型和运算符
虽然js是弱数据类型的语言,但是js中也存在数据类型,js中的数据类型分为 :原始类型 和 引用类型,具体有如下类型
数据类型 描述 number 数字(整数、小数、NaN(Not a Number)) string 字符串,单双引皆可 boolean 布尔。true,false null 对象为空(也可能是Object,这个是JavaScript最初实现的时候的一个错误。可以认为是对象的占位符,但本质上还是原始类型) undefined 当声明的变量未初始化时,该变量的默认值是 undefined 使用typeof函数可以返回变量的数据类型,接下来我们需要通过书写代码来演示js中的数据类型
熟悉了js的数据类型了,那么我们需要学习js中的运算法,js中的运算规则绝大多数还是和java中一致的,具体运算符如下:
运算规则 运算符 算术运算符 + , - , * , / , % , ++ , – 赋值运算符 = , += , -= , *= , /= , %= 比较运算符 > , < , >= , <= , != , == , === 注意 == 会进行类型转换,=== 不会进行类型转换(10 == “10”) 逻辑运算符 && , || , ! 三元运算符 条件表达式 ? true_value: false_value 类型转换:
- 字符串类型转数字:如果字面值是数字,那就是对应的数字,如果不是数字,则会转化为NaN。
- 其他类型转boolean:
- 数字:0和NaN是false,其他就是true
- String:空字符串是false,其他是true
- null和未定义:均为false
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//原始数据类型
alert(typeof 3); //number
alert(typeof 3.14); //number
alert(typeof "A"); //string
alert(typeof 'Hello');//string
alert(typeof true); //boolean
alert(typeof false);//boolean
alert(typeof null); //object
var a ;
alert(typeof a); //undefined
var age = 20;
var _age = "20";
var $age = 20;
alert(age == _age);//true ,只比较值
alert(age === _age);//false ,类型不一样
alert(age === $age);//true ,类型一样,值一样
alert(parseInt("12")); //12
alert(parseInt("12A45")); //12
alert(parseInt("A45"));//NaN (not a number)流程控制语句if,switch,for等和java保持一致,此处不再演示
函数
在java中我们为了提高代码的复用性,可以使用方法。同样,在JavaScript中可以使用函数来完成相同的事情。JavaScript中的函数被设计为执行特定任务的代码块,通过关键字function来定义。接下来我们学习一下JavaScript中定义函数的2种语法
第一种定义格式如下:
1
2
3function 函数名(参数1,参数2..){
要执行的代码
}因为JavaScript是弱数据类型的语言,所以有如下几点需要注意:
- 形式参数不需要声明类型,并且JavaScript中不管什么类型都是let或者var去声明,加上也没有意义。
- 返回值也不需要声明类型,直接return即可
如下示例:
1
2
3function add(a, b){
return a + b;
}第二种可以通过var去定义函数的名字,具体格式如下:
1
2
3var functionName = function (参数1,参数2..){
//要执行的代码
}接下来我们按照上述的格式,修改代码如下:只需要将第一种定义方式注释掉,替换成第二种定义方式即可,函数的调用不变。
我们在调用add函数时,再添加2个参数,修改代码如下:
1
var result = add(10,20,30,40);
浏览器打开,发现没有错误,并且依然弹出30,这是为什么呢?
因为在JavaScript中,函数的调用只需要名称正确即可,参数列表不管的。如上述案例,10传递给了变量a,20传递给了变量b,而30和40没有变量接受,但是不影响函数的正常调用。
对象
Array对象
Array对象时用来定义数组的。常用语法格式有如下2种:
方式1:
1
var 变量名 = new Array(元素列表);
例如:
1
var arr = new Array(1,2,3,4); //1,2,3,4 是存储在数组中的数据(元素)
方式2:
1
var 变量名 = [ 元素列表 ];
例如:
1
var arr = [1,2,3,4]; //1,2,3,4 是存储在数组中的数据(元素)
数组定义好了,那么我们该如何获取数组中的值呢?和java中一样,需要通过索引来获取数组中的值。语法如下:
1
arr[索引] = 值;
与java中不一样的是,JavaScript中数组相当于java中的集合,数组的长度是可以变化的。而且JavaScript是弱数据类型的语言,所以数组中可以存储任意数据类型的值。接下来我们通过代码来演示上述特点。
注释掉之前的代码,添加如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13//特点: 长度可变 类型可变
var arr = [1,2,3,4];
arr[10] = 50;
console.log(arr[10]); // 50
console.log(arr[9]); // undefined
console.log(arr[8]); // undefined
arr[9] = "A";
arr[8] = true;
console.log(arr);
// 没有问题上述代码定义的arr变量中,数组的长度是4,但是我们直接再索引10的位置直接添加了数据10,并且输出索引为10的位置的元素
官方文档中提供了Array的很多属性和方法,但是我们只学习常用的属性和方法,如下图所示:
属性:
属性 描述 length 设置或返回数组中元素的数量。 方法:
方法方法 描述 forEach() 遍历数组中的每个有值得元素,并调用一次传入的函数 push() 将新元素添加到数组的末尾,并返回新的长度 splice() 从数组中删除元素 length属性:
length属性可以用来获取数组的长度,所以我们可以借助这个属性,来遍历数组中的元素,添加如下代码:
1
2
3
4
5var arr = [1,2,3,4];
arr[10] = 50;
for (let i = 0; i < arr.length; i++) {
console.log(arr[i]);
}forEach()函数
首先我们学习forEach()方法,顾名思义,这是用来遍历的,那么遍历做什么事呢?所以这个方法的参数,需要传递一个函数,而且这个函数接受一个参数,就是遍历时数组的值。修改之前的遍历代码如下:
1
2
3
4//e是形参,接受的是数组遍历时的值
arr.forEach(function(e){
console.log(e);
})当然了,在ES6中,引入箭头函数的写法,语法类似java中lambda表达式,修改上述代码如下:
1
2
3arr.forEach((e) => {
console.log(e);
})浏览器输出结果如下:注意的是,没有元素的内容是不会输出的,因为forEach只会遍历有值的元素 。而for循环无论有值还是没值都会遍历。
push()函数
push()函数是用于向数组的末尾添加元素的,其中函数的参数就是需要添加的元素,编写如下代码:向数组的末尾添加3个元素
1
2
3//push: 添加元素到数组末尾
arr.push(7,8,9);
console.log(arr);splice()函数
splice()函数用来数组中的元素,函数中填入2个参数。
参数1:表示从哪个索引位置删除
参数2:表示删除元素的个数
如下代码表示:从索引2的位置开始删,删除2个元素
1
2
3//splice: 删除元素
arr.splice(2,2);
console.log(arr);浏览器执行效果如下:元素3和4被删除了,元素3是索引2
String对象
String对象的创建方式有2种:
方式1:
1
var 变量名 = new String("…") ; //方式一
例如:
1
var str = new String("Hello String");
方式2:
1
var 变量名 = "…" ; //方式二
例如:
1
var str = 'Hello String';
String对象也提供了一些常用的属性和方法,如下表格所示:
属性:
属性 描述 length 字符串的长度。 方法:
方法 描述 charAt() 返回在指定位置的字符。 indexOf() 检索字符串。 trim() 去除字符串两边的空格 substring() 提取字符串中两个指定的索引号之间的字符。 length属性:
length属性可以用于返回字符串的长度,添加如下代码:
1
2//length
console.log(str.length);charAt()函数:
charAt()函数用于返回在指定索引位置的字符,函数的参数就是索引。添加如下代码:
1
console.log(str.charAt(4));
indexOf()函数
indexOf()函数用于检索指定内容在字符串中的索引位置的,返回值是索引,参数是指定的内容。不存在的会返回-1.添加如下代码:
1
console.log(str.indexOf("lo"));
trim()函数
trim()函数用于去除字符串两边的空格的。添加如下代码:
1
2var s = str.trim();
console.log(s.length);substring()函数
substring()函数用于截取字符串的,函数有2个参数。
参数1:表示从那个索引位置开始截取。包含
参数2:表示到那个索引位置结束。不包含
1
console.log(s.substring(0,5));
JSON对象
在 JavaScript 中自定义对象特别简单,其语法格式如下:
1
2
3
4
5
6
7var 对象名 = {
属性名1: 属性值1,
属性名2: 属性值2,
属性名3: 属性值3,
函数名称: function(形参列表){}
};我们可以通过如下语法调用属性:
1
对象名.属性名
通过如下语法调用函数:
1
对象名.函数名()
比如说:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<script>
//自定义对象
var user = {
name: "Tom",
age: 10,
gender: "male",
// eat: function(){
// console.log("用膳~");
// }
eat(){
console.log("用膳~");
}
// 可以把冒号和function给删掉。
}
console.log(user.name);
user.eat();
<script>JSON对象:JavaScript Object Notation,JavaScript对象标记法。是通过JavaScript标记法书写的文本。其格式如下:
1
2
3
4
5{
"key":value,
"key":value,
"key":value
}其中,key必须使用引号并且是双引号标记,value可以是任意数据类型。可以是基本的数据类型,可以是一个数组,当然也可以是另外一个json。那么json这种数据格式的文本到底应用在企业开发的什么地方呢?– 经常用来作为前后台交互的数据载体。
接下来我们通过代码来演示json对象:注释掉之前的代码,编写代码如下:
1
2
3var jsonstr = '{"name":"Tom", "age":18, "addr":["北京","上海","西安"]}';
alert(jsonstr.name);
// 输出undefined为什么呢?因为上述是一个json字符串,不是json对象,所以我们需要借助如下函数来进行json字符串和json对象的转换。添加代码如下:
1
2var obj = JSON.parse(jsonstr);
alert(obj.name);当然了,我们也可以通过如下函数将json对象再次转换成json字符串。添加如下代码:
1
alert(JSON.stringify(obj));
BOM对象
OM的全称是Browser Object Model,翻译过来是浏览器对象模型。也就是JavaScript将浏览器的各个组成部分封装成了对象。我们要操作浏览器的部分功能,可以通过操作BOM对象的相关属性或者函数来完成。例如:我们想要将浏览器的地址改为
http://www.baidu.com,我们就可以通过BOM中提供的location对象的href属性来完成,代码如下:location.href='http://www.baidu.com'BOM中提供了如下5个对象:
对象名称 描述 Window 浏览器窗口对象 Navigator 浏览器对象 Screen 屏幕对象 History 历史记录对象 Location d地址栏对象 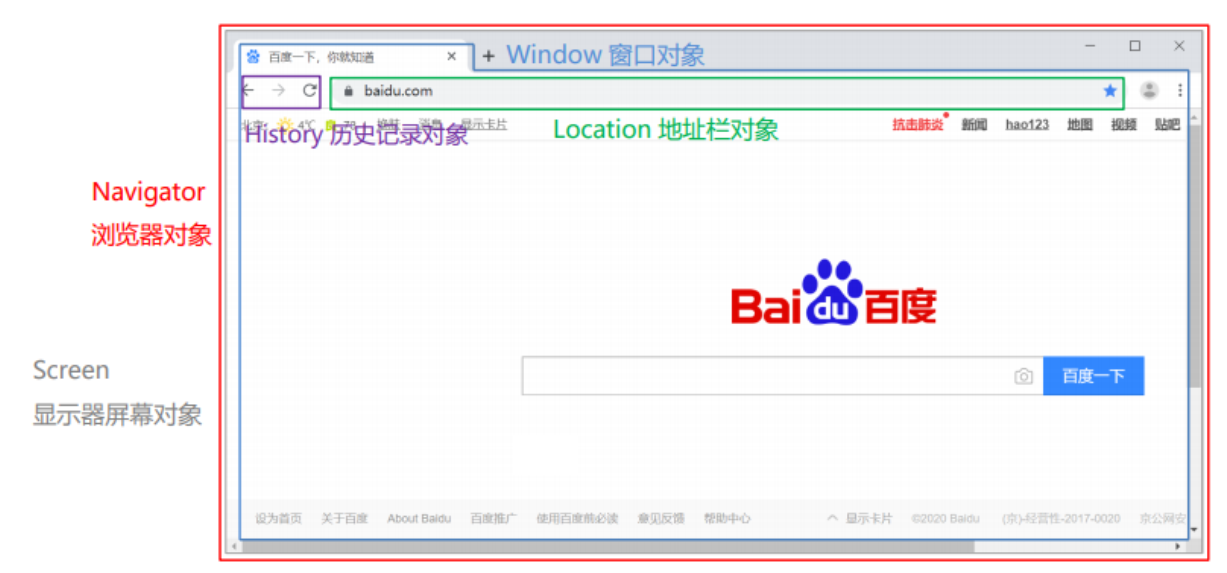
Window对象
如何使用window对象?可以直接写
window.,然后window.可以省略。window对象指的是浏览器窗口对象,是JavaScript的全部对象,所以对于window对象,我们可以直接使用,并且对于window对象的方法和属性,我们可以省略window.例如:我们之前学习的alert()函数其实是属于window对象的,其完整的代码如下:
1
window.alert('hello');
其可以省略window. 所以可以简写成
1
alert('hello')
所以对于window对象的属性和方法,我们都是采用简写的方式。window提供了很多属性和方法,下表列出了常用属性和方法
window对象提供了获取其他BOM对象的属性:
属性 描述 history 用于获取history对象 location 用于获取location对象 Navigator 用于获取Navigator对象 Screen 用于获取Screen对象 也就是说我们要使用location对象,只需要通过代码
window.location或者简写location即可使用window也提供了一些常用的函数,如下表格所示:
函数 描述 alert() 显示带有一段消息和一个确认按钮的警告框。 comfirm() 显示带有一段消息以及确认按钮和取消按钮的对话框。 setInterval() 按照指定的周期(以毫秒计)来调用函数或计算表达式。 setTimeout() 在指定的毫秒数后调用函数或计算表达式。 alert()函数:弹出警告框,函数的内容就是警告框的内容
1
2
3
4
5<script>
//window对象是全局对象,window对象的属性和方法在调用时可以省略window.
window.alert("Hello BOM");
alert("Hello BOM Window");
</script>浏览器打开,依次弹框,此处只截图一张
confirm()函数:弹出确认框,并且提供用户2个按钮,分别是确认和取消。
添加如下代码:
1
confirm("您确认删除该记录吗?");
但是我们怎么知道用户点击了确认还是取消呢?所以这个函数有一个返回值,当用户点击确认时,返回true,点击取消时,返回false。我们根据返回值来决定是否执行后续操作。修改代码如下:再次运行,可以查看返回值true或者false
1
2var flag = confirm("您确认删除该记录吗?");
alert(flag);setInterval(fn,毫秒值):定时器,用于周期性的执行某个功能,并且是循环执行。该函数需要传递2个参数:
fn:函数,需要周期性执行的功能代码
毫秒值:间隔时间
注释掉之前的代码,添加代码如下:
1
2
3
4
5
6//定时器 - setInterval -- 周期性的执行某一个函数
var i = 0;
setInterval(function(){
i++;
console.log("定时器执行了"+i+"次");
},2000);刷新页面,浏览器每个一段时间都会在控制台输出。
setTimeout(fn,毫秒值) :定时器,只会在一段时间后执行一次功能。参数和上述setInterval一致
注释掉之前的代码,添加代码如下:
1
2
3
4//定时器 - setTimeout -- 延迟指定时间执行一次
setTimeout(function(){
alert("JS");
},3000);浏览器打开,3s后弹框,关闭弹框,发现再也不会弹框了。
Location对象
location是指代浏览器的地址栏对象,对于这个对象,我们常用的是href属性,用于获取或者设置浏览器的地址信息,添加如下代码:
1
2
3
4//获取浏览器地址栏信息
alert(location.href);
//设置浏览器地址栏信息,设置完了之后浏览器会自动跳转
location.href = "https://www.sukunahust.moe";浏览器效果如下:首先弹框展示浏览器地址栏信息, 然后点击确定后,因为我们设置了地址栏信息,所以浏览器跳转。
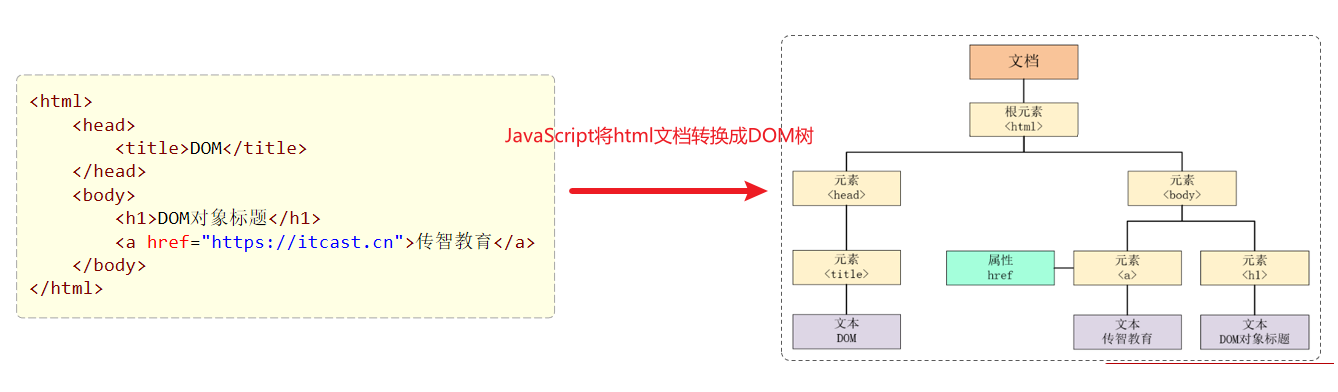
DOM对象
DOM:Document Object Model 文档对象模型。也就是 JavaScript 将 HTML 文档的各个组成部分封装为对象。封装的对象分为:
- Document:整个文档对象
- Element:元素对象
- Attribute:属性对象
- Text:文本对象
- Comment:注释对象
如下图,左边是 HTML 文档内容,右边是 DOM 树
那么我们学习DOM技术有什么用呢?主要作用如下:
- 改变 HTML 元素的内容
- 改变 HTML 元素的样式(CSS)
- 对 HTML DOM 事件作出反应
- 添加和删除 HTML 元素
HTML中的Element对象可以通过Document对象获取,而Document对象是通过window对象获取的。document对象提供的用于获取Element元素对象的api如下表所示:
函数 描述 document.getElementById() 根据id属性值获取,返回单个Element对象 document.getElementsByTagName() 根据标签名称获取,返回Element对象数组 document.getElementsByName() 根据name属性值获取,返回Element对象数组 document.getElementsByClassName() 根据class属性值获取,返回Element对象数组 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>JS-对象-DOM</title>
</head>
<body>
<img id="h1" src="img/off.gif"> <br><br>
<div class="cls">传智教育</div> <br>
<div class="cls">黑马程序员</div> <br>
<input type="checkbox" name="hobby"> 电影
<input type="checkbox" name="hobby"> 旅游
<input type="checkbox" name="hobby"> 游戏
</body>
</html>document.getElementById(): 根据标签的id属性获取标签对象,id是唯一的,所以获取到是单个标签对象。
添加如下代码:
1
2
3
4
5
6<script>
//1.1 获取元素-根据ID获取
var img = document.getElementById('h1');
alert(img);
// object HTMLImageElement
</script>document.getElementsByTagName() : 根据标签的名字获取标签对象,同名的标签有很多,所以返回值是数组。
添加如下代码:
1
2
3
4
5
6//1.2 获取元素-根据标签获取 - div
var divs = document.getElementsByTagName('div');
for (let i = 0; i < divs.length; i++) {
alert(divs[i]);
// object HTMLDivElement
}document.getElementsByName() :根据标签的name的属性值获取标签对象,name属性值可以重复,所以返回值是一个数组。
添加如下代码:
1
2
3
4
5
6//1.3 获取元素-根据name属性获取
var ins = document.getElementsByName('hobby');
for (let i = 0; i < ins.length; i++) {
alert(ins[i]);
// object HTMLInputElement
}document.getElementsByClassName() : 根据标签的class属性值获取标签对象,class属性值也可以重复,返回值是数组。
添加如下图所示的代码:
1
2
3
4
5
6//1.4 获取元素-根据class属性获取
var divs = document.getElementsByClassName('cls');
for (let i = 0; i < divs.length; i++) {
alert(divs[i]);
// object HTMLDivElement
}对象可以通过属性的改变进行操作,可以通过查询文档来对属性进行改变。
1
2
3
4var divs = document.getElementsByClassName('cls');
var div1 = divs[0];
div1.innerHTML = "XXXX";事件监听
什么是事件呢?HTML事件是发生在HTML元素上的 “事情”,例如:
- 按钮被点击
- 鼠标移到元素上
- 输入框失去焦点
- ……..
而我们可以给这些事件绑定函数,当事件触发时,可以自动的完成对应的功能。
事件绑定
JavaScript对于事件的绑定提供了2种方式:
方式1:通过html标签中的事件属性进行绑定,下面的例子就是onclick
例如一个按钮,我们对于按钮可以绑定单机事件,可以借助标签的onclick属性,属性值指向一个函数。
1
<input type="button" id="btn1" value="事件绑定1" onclick="on()">
很明显没有on函数,所以我们需要创建该函数,代码如下:
1
2
3
4
5<script>
function on(){
alert("按钮1被点击了...");
}
</script>方式2:通过DOM中Element元素的事件属性进行绑定
依据我们学习过得DOM的知识点,我们知道html中的标签被加载成element对象,所以我们也可以通过element对象的属性来操作标签的属性。此时我们再次添加一个按钮,代码如下:
1
<input type="button" id="btn2" value="事件绑定2">
我们可以先通过id属性获取按钮对象,然后操作对象的onclick属性来绑定事件,代码如下:
1
2
3document.getElementById('btn2').onclick = function(){
alert("按钮2被点击了...");
}常见事件
下面就给大家列举一些比较常用的事件属性
事件属性名 说明 onclick 鼠标单击事件 onblur 元素失去焦点 onfocus 元素获得焦点 onload 某个页面或图像被完成加载 onsubmit 当表单提交时触发该事件 onmouseover 鼠标被移到某元素之上 onmouseout 鼠标从某元素移开 Vue
通过我们学习的html+css+js已经能够开发美观的页面了,但是开发的效率还有待提高,那么如何提高呢?我们先来分析下页面的组成。一个完整的html页面包括了视图和数据,数据是通过请求 从后台获取的,那么意味着我们需要将后台获取到的数据呈现到页面上,很明显, 这就需要我们使用DOM操作。正因为这种开发流程,所以我们引入了一种叫做MVVM(Model-View-ViewModel)的前端开发思想,即让我们开发者更加关注数据,而非数据绑定到视图这种机械化的操作。那么具体什么是MVVM思想呢?
MVVM:其实是Model-View-ViewModel的缩写,有3个单词,具体释义如下:
- Model: 数据模型,特指前端中通过请求从后台获取的数据(原始数据和数据操作)
- View: 视图,用于展示数据的页面,可以理解成我们的html+css搭建的页面,但是没有数据(DOM元素)
- ViewModel: 数据绑定到视图,负责将数据(Model)通过JavaScript的DOM技术,将数据展示到视图(View)上
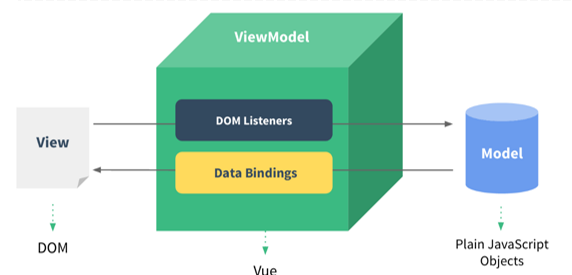
快速入门
第一步:在VS Code中创建名为html的文件,引入vue.js文件,最好放到js文件夹中。
第二步:(最好在head)然后编写<script>标签来引入vue.js文件,代码如下:
1
<script src="js/vue.js"></script>
第三步:在js代码区域定义vue对象,代码如下:
1
2
3
4
5
6
7
8
9<script>
//定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
message: "Hello Vue"
}
})
</script>在创建vue对象时,有几个常用的属性:
- el: 用来指定哪儿些标签受 Vue 管理。 该属性取值
#app中的app需要是受管理的标签的id属性值。(类似于css的选择器) - data: 用来定义数据模型
- methods: 用来定义函数。这个我们在后面就会用到
第四步:在html区域编写视图,其中
{{}}是插值表达式,用来将vue对象中定义的model展示到页面上的。插值表达式中可以进行运算,可以是集合或者是对象。1
2
3
4
5
6
7
8<body>
<div id="app">
<!-- input框的内容和message这个数据进行绑定,input能改变message的值-->
<input type="text" v-model="message">
{{message}}
<!-- 这是一个嵌套表达式,把message的内容直接copy过来-->
</div>
</body>双向数据绑定:就是视图可能会改变model的数据,model也有可能改变视图。
在Vue中,el属性用于指定当前Vue实例要挂载到的DOM元素。它可以是一个CSS选择器字符串,也可以是一个已存在的HTMLElement实例。如果没有提供el属性,Vue实例将不会自动挂载,你需要手动调用*vm.$mount()*来启动挂载过程1。
常用指令
在上述的快速入门中,我们发现了html中输入了一个没有学过的属性
v-model,这个就是vue的指令。指令:HTML 标签上带有 v- 前缀的特殊属性,不同指令具有不同含义。例如:v-if,v-for…
在vue中,通过大量的指令来实现数据绑定到视图的,所以接下来我们需要学习vue的常用指令,如下表所示:
指令 作用 v-bind 为HTML标签绑定属性值,如设置 href , css样式等 v-model 在表单元素上创建双向数据绑定 v-on 为HTML标签绑定事件 v-if 条件性的渲染某元素,判定为true时渲染,否则不渲染 v-else v-else-if v-show 根据条件展示某元素,区别在于切换的是display属性的值 v-for 列表渲染,遍历容器的元素或者对象的属性 v-bind
v-bind: 为HTML标签绑定属性值,如设置 href , css样式等。当vue对象中的数据模型发生变化时,标签的属性值会随之发生变化。
然后准备好如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Vue-指令-v-bind</title>
<script src="js/vue.js"></script>
</head>
<body>
<div id="app">
<a >链接1</a>
<a >链接2</a>
<input type="text" >
</div>
</body>
<script>
//定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
url: "https://www.baidu.com"
}
method:{
}
})
</script>
</html>在上述的代码中,我们需要给<a>标签的href属性赋值,并且值应该来自于vue对象的数据模型中的url变量。所以编写如下代码:
1
<a v-bind:href="url">链接1</a>
在上述的代码中,v-bind指令是可以省略的,但是:不能省略,所以第二个超链接的代码编写如下:
1
<a :href="url">链接2</a>
一般来说v-bind就是单向链接,就是将herf这个属性的值和model中的url这个属性绑定了。
v-model
v-model: 在表单元素上创建双向数据绑定。什么是双向?(改变model中元素或者叫变量的值)【当然所有元素都可用】
- vue对象的data属性中的数据变化,视图展示会一起变化
- 视图数据发生变化,vue对象的data属性中的数据也会随着变化。
data属性中数据变化,我们知道可以通过赋值来改变,但是视图数据为什么会发生变化呢?只有表单项标签!所以双向绑定一定是使用在表单项标签上的。编写如下代码:
1
<input type="text" v-model="url">
打开浏览器,我们修改表单项标签,发现vue对象data中的数据也发生了变化
通过上图我们发现,我们只是改变了表单数据,那么我们之前超链接的绑定的数据值也发生了变化,为什么?
就是因为我们双向绑定,在视图发生变化时,同时vue的data中的数据模型也会随着变化。那么这个在企业开发的应用场景是什么?
双向绑定的作用:可以获取表单的数据的值,然后提交给服务器
上面的两个命令进行绑定的时候,必须要在model中进行声明。
v-on
v-on: 用来给html标签绑定事件的。需要注意的是如下2点:
v-on语法给标签的事件绑定的函数,必须是vue对象种声明的函数
v-on语法绑定事件时,事件名相比较js中的事件名,没有on
例如:在js中,事件绑定demo函数
1
<input onclick="demo()">
vue中,事件绑定demo函数
1
<input v-on:click="demo()">
这个函数定义在model中的method域
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Vue-指令-v-on</title>
<script src="js/vue.js"></script>
</head>
<body>
<div id="app">
<input type="button" value="点我一下" v-on:click="handle()">
<input type="button" value="点我一下" @click="handle()">
</div>
</body>
<script>
//定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
},
// 在method中定义事件
methods: {
handle: function(){
alert("你点我了一下...");
}
}
})
</script>
</html>v-if、v-else-if、v-else
请看下面的例子,使用方法和C/Java类似。注意,判断的条件要用””包裹起来。
1
2
3
4年龄<input type="text" v-model="age">经判定,为:
<span v-if="age <= 35">年轻人(35及以下)</span>
<span v-else-if="age > 35 && age < 60">中年人(35-60)</span>
<span v-else>老年人(60及以上)</span>v-show命令
v-show和v-if的作用效果是一样的,只是原理不一样。复制上述html代码,修改v-if指令为v-show指令,代码如下:
1
2
3
4年龄<input type="text" v-model="age">经判定,为:
<span v-show="age <= 35">年轻人(35及以下)</span>
<span v-show="age > 35 && age < 60">中年人(35-60)</span>
<span v-show="age >= 60">老年人(60及以上)</span>可以发现,浏览器呈现的效果是一样的,但是浏览器中html源码不一样。v-if指令,不满足条件的标签代码直接没了,而v-show指令中,不满足条件的代码依然存在,只是添加了css样式来控制标签不去显示。
v-for
v-for: 从名字我们就能看出,这个指令是用来遍历的。其语法格式如下:
1
2
3<标签 v-for="变量名 in 集合模型数据">
{{变量名}}
</标签>需要注意的是:需要循环哪个标签,v-for 指令就写在那个标签上。(不要写在父标签上)
有时我们遍历时需要使用索引,那么v-for指令遍历的语法格式如下:(索引从0开始)
1
2
3
4<标签 v-for="(变量名,索引变量) in 集合模型数据">
<!--索引变量是从0开始,所以要表示序号的话,需要手动的加1-->
{{索引变量 + 1}} {{变量名}}
</标签>v-for相当于生成了若干个格式一致的标签,标签的定义是声明v-for的标签里。
引入model中元素的方式:v-model,v-for。只用在属性里:v-bind
生命周期
vue的生命周期:指的是vue对象从创建到销毁的过程。vue的生命周期包含8个阶段:每触发一个生命周期事件,会自动执行一个生命周期方法,这些生命周期方法也被称为钩子方法。其完整的生命周期如下图所示:
状态 阶段周期 beforeCreate 创建前 created 创建后 beforeMount 挂载前 mounted 挂载完成 beforeUpdate 更新前 updated 更新后 beforeDestroy 销毁前 destroyed 销毁后 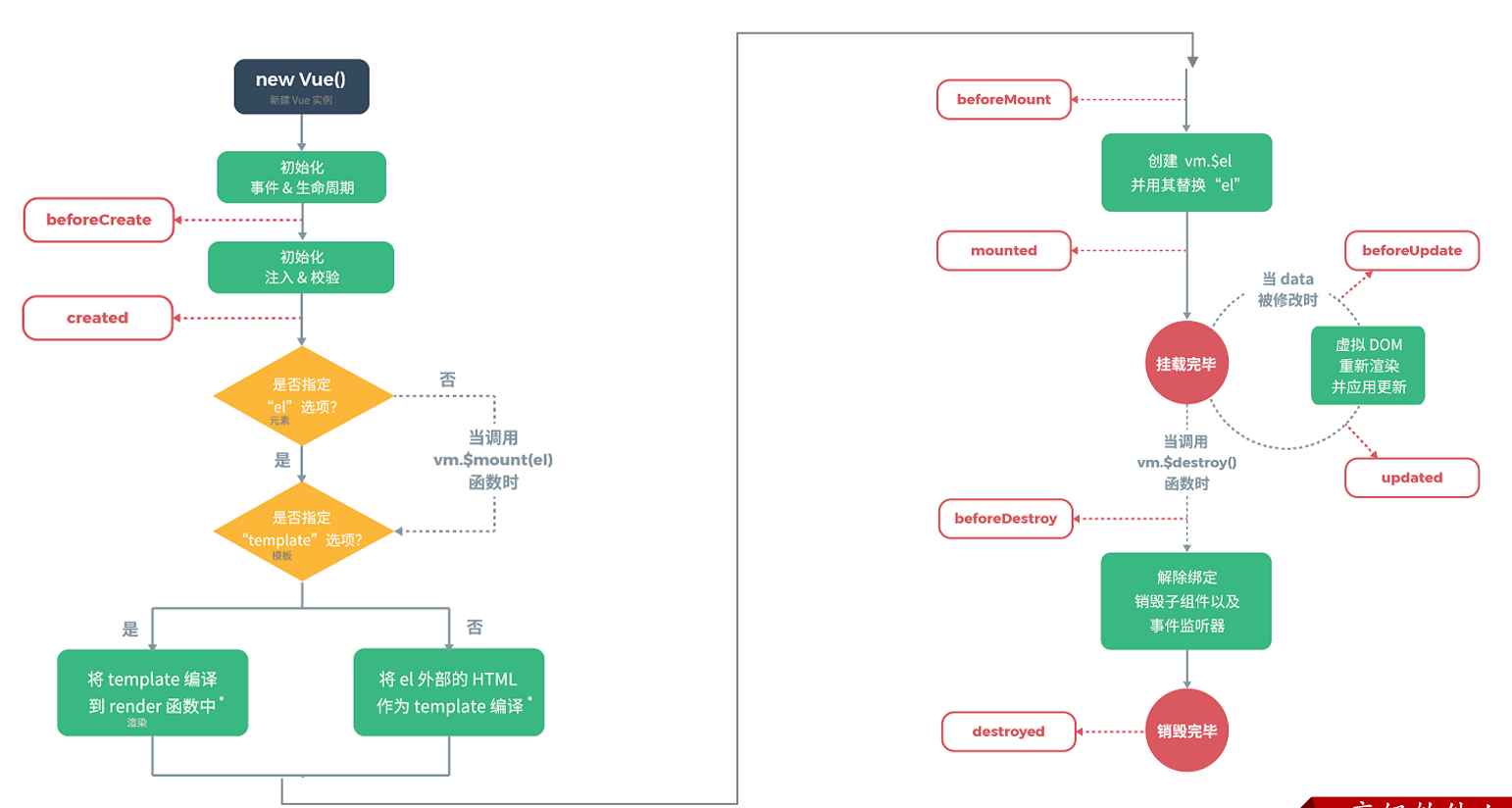
其中我们需要重点关注的是**mounted,**其他的我们了解即可。
mounted:挂载完成,Vue初始化成功,HTML页面渲染成功。以后我们一般用于页面初始化自动的ajax请求后台数据
然后我们编写mounted声明周期的钩子函数,与methods同级,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<script>
//定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
},
methods: {
},
mounted () {
alert("vue挂载完成,发送请求到服务端")
}
})
</script>浏览器打开,运行结果如下:我们发现,自动打印了这句话,因为页面加载完成,vue对象创建并且完成了挂在,此时自动触发mounted所绑定的钩子函数,然后自动执行,弹框。
Ajax与Element
Ajax
原生Ajax
Ajax: 全称Asynchronous JavaScript And XML,异步的JavaScript和XML。其作用有如下2点:
与服务器进行数据交换:通过Ajax可以给服务器发送请求,并获取服务器响应的数据。前端资源被浏览器解析,但是前端页面上缺少数据,前端可以通过Ajax技术,向后台服务器发起请求,后台服务器接受到前端的请求,从数据库中获取前端需要的资源,然后响应给前端,前端在通过我们学习的vue技术,可以将数据展示到页面上,这样用户就能看到完整的页面了。此处可以对比JavaSE中的网络编程技术来理解。
异步交互:可以在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页的技术,如:搜索联想、用户名是否可用的校验等等。当我们再百度搜索java时,下面的联想数据是通过Ajax请求从后台服务器得到的,在整个过程中,我们的Ajax请求不会导致整个百度页面的重新加载,并且只针对搜索栏这局部模块的数据进行了数据的更新,不会对整个页面的其他地方进行数据的更新,这样就大大提升了页面的加载速度,用户体验高。(异步是浏览器页面发送请求给服务器,在服务器处理请求的过程中,浏览器页面还可以做其他的操作。)
客户端的Ajax请求代码如下有如下4步,接下来我们跟着步骤一起操作一下。
第一步:提供如下代码,主要是按钮绑定单击事件,我们希望点击按钮,来发送ajax请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>原生Ajax</title>
</head>
<body>
<input type="button" value="获取数据" onclick="getData()">
<div id="div1"></div>
</body>
<script>
function getData(){
}
</script>
</html>第二步:创建XMLHttpRequest对象,用于和服务器交换数据,也是原生Ajax请求的核心对象,提供了各种方法。代码如下:
1
2//1. 创建XMLHttpRequest
var xmlHttpRequest = new XMLHttpRequest();第三步:调用对象的open()方法设置请求的参数信息,例如请求地址,请求方式。然后调用send()方法向服务器发送请求,代码如下:
1
2
3//2. 发送异步请求
xmlHttpRequest.open('GET','http://yapi.smart-xwork.cn/mock/169327/emp/list');
xmlHttpRequest.send();//发送请求第四步:我们通过绑定事件的方式,来获取服务器响应的数据。
1
2
3
4
5
6
7//3. 获取服务响应数据
xmlHttpRequest.onreadystatechange = function(){
//此处判断 4表示浏览器已经完全接受到Ajax请求得到的响应, 200表示这是一个正确的Http请求,没有错误
if(xmlHttpRequest.readyState == 4 && xmlHttpRequest.status == 200){
document.getElementById('div1').innerHTML = xmlHttpRequest.responseText;
}
}
Axios
Axios的使用比较简单,主要分为2步:
引入Axios文件
1
<script src="js/axios-0.18.0.js"></script>
使用Axios发送请求,并获取响应结果,官方提供的api很多,此处给出2种,如下
发送 get 请求
1
2
3
4
5
6axios({
method:"get",
url:"http://localhost:8080/ajax-demo1/aJAXDemo1?username=zhangsan"
}).then(function (resp){
alert(resp.data);
})发送 post 请求
1
2
3
4
5
6
7
8axios({
method:"post",
url:"http://localhost:8080/ajax-demo1/aJAXDemo1",
data:"username=zhangsan"// 请求体
}).then(function (resp){
alert(resp.data);
});
// .then()就是成功回调函数
axios()是用来发送异步请求的,小括号中使用 js的JSON对象传递请求相关的参数:
- method属性:用来设置请求方式的。取值为 get 或者 post。
- url属性:用来书写请求的资源路径。如果是 get 请求,需要将请求参数拼接到路径的后面,格式为: url?参数名=参数值&参数名2=参数值2。
- data属性:作为请求体被发送的数据。也就是说如果是 post 请求的话,数据需要作为 data 属性的值。
then() 需要传递一个匿名函数。我们将 then()中传递的匿名函数称为 回调函数,意思是该匿名函数在发送请求时不会被调用,而是在成功响应后调用的函数。而该回调函数中的 resp 参数是对响应的数据进行封装的对象,通过 resp.data 可以获取到响应的数据。
Axios还针对不同的请求,提供了别名方式的api,具体如下:
方法 描述 axios.get(url [, config]) 发送get请求 axios.delete(url [, config]) 发送delete请求 axios.post(url [, data[, config]]) 发送post请求 axios.put(url [, data[, config]]) 发送put请求 我们目前只关注get和post请求,所以在上述的入门案例中,我们可以将get请求代码改写成如下:
1
2
3axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => {
console.log(result.data);
})post请求改写成如下:
1
2
3axios.post("http://yapi.smart-xwork.cn/mock/169327/emp/deleteById","id=1").then(result => {
console.log(result.data);
})前端工程化
前后端分离开发
我们将原先的工程分为前端工程和后端工程这2个工程,然后前端工程交给专业的前端人员开发,后端工程交给专业的后端人员开发。前端页面需要数据,可以通过发送异步请求,从后台工程获取。但是,我们前后台是分开来开发的,那么前端人员怎么知道后台返回数据的格式呢?后端人员开发,怎么知道前端人员需要的数据格式呢?所以针对这个问题,我们前后台统一指定一套规范!我们前后台开发人员都需要遵循这套规范开发,这就是我们的接口文档。接口文档有离线版和在线版本,接口文档示可以查询资料/接口文档示例里面的资料。那么接口文档的内容怎么来的呢?是我们后台开发者根据产品经理提供的产品原型和需求文档所撰写出来的,产品原型示例可以参考今天提供页面原型里面的资料。这些接口文档一般是产品经理根据客户的需求制作的接口文档和页面原型。
那么基于前后台分离开发的模式下,我们后台开发者开发一个功能的具体流程如何呢?
- 需求分析:首先我们需要阅读需求文档,分析需求,理解需求。
- 接口定义:查询接口文档中关于需求的接口的定义,包括地址,参数,响应数据类型等等
- 前后台并行开发:各自按照接口文档进行开发,实现需求
- 测试:前后台开发完了,各自按照接口文档进行测试
- 前后段联调测试:前段工程请求后端工程,测试功能
YAPI
前后台分离开发中,我们前后台开发人员都需要遵循接口文档,所以接下来我们介绍一款撰写接口文档的平台。
YApi 是高效、易用、功能强大的 api 管理平台,旨在为开发、产品、测试人员提供更优雅的接口管理服务。
其官网地址:http://yapi.smart-xwork.cn/
YApi主要提供了2个功能:
- API接口管理:根据需求撰写接口,包括接口的地址,参数,响应等等信息。
- Mock服务:模拟真实接口,生成接口的模拟测试数据,用于前端的测试。
一般来说,一个API文档需要有,请求地址,请求头,请求内容和回复内容四个部分。请求内容和回复内容有字段、字段类型和必须与否三部分。
前端工程化简介
所以现在企业开发中更加讲究前端工程化方式的开发,主要包括如下4个特点
- 模块化:将js和css等,做成一个个可复用模块
- 组件化:我们将UI组件,css样式,js行为封装成一个个的组件,便于管理
- 规范化:我们提供一套标准的规范的目录接口和编码规范,所有开发人员遵循这套规范
- 自动化:项目的构建,测试,部署全部都是自动完成
所以对于前端工程化,说白了,就是在企业级的前端项目开发中,把前端开发所需要的工具、技术、流程、经验进行规范化和标准化。从而提升开发效率,降低开发难度等等。接下来我们就需要学习vue的官方提供的脚手架帮我们完成前端的工程化。
Vue-cil
我们的前端工程化是通过vue官方提供的脚手架Vue-cli来完成的,用于快速的生成一个Vue的项目模板。Vue-cli主要提供了如下功能:
- 统一的目录结构
- 本地调试
- 热部署:应用程序的代码变动了,不需要再次运行就可以再次运行。
- 单元测试
- 集成打包上线
我们需要运行Vue-cli,需要依赖NodeJS,NodeJS是前端工程化依赖的环境。所以我们需要先安装NodeJS,然后才能安装Vue-cli
环境准备好了,接下来我们需要通过Vue-cli创建一个vue项目,然后再学习一下vue项目的目录结构。Vue-cli提供了如下2种方式创建vue项目:
命令行:直接通过命令行方式创建vue项目
1
vue create vue-project0
图形化界面:通过命令先进入到图形化界面,然后再进行vue工程的创建
1
vue ui
使用图形化界面创建Vue的时候需要:
- 包管理器使用npm
- 预设模板为手动
- 功能使用Router(路由功能)
- Vue版本选择2.x
- 语法检查规范选择 第一个 (error prevention only)
标准项目中目录结构:
- node_module:存放整个项目的依赖包(可以认为是很多js文件和css文件)
- public:存放项目的静态文件
- src:存放项目的源代码
- assets:静态资源
- component:可重用的组件
- router:路由配置
- views:视图组件(页面)
- App.vue:(入口页面和根组件)
- main.js(入口js文件)
- package.json:模块基本信息(项目开发所需的模块和模块的版本信息)
- vue.config.js:保存Vue配置的文件
那么vue项目开发好了,我们应该怎么运行vue项目呢?主要提供了2种方式
第一种方式:通过VS Code提供的图形化界面
第二种方式:命令行方式
直接基于cmd命令窗口,在vue目录下,执行输入命令
npm run serve即可,如下图所示:
对于8080端口,经常被占用,所以我们可以去修改默认的8080端口。我们修改vue.config.js文件的内容,添加如下代码:
1
2
3
4
5
6
7const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({
transpileDependencies: true,
devServer:{
port:7000
}
})我们自习观察发现,index.html的代码很简洁,但是浏览器所呈现的index.html内容却很丰富,代码和内容不匹配,所以vue是如何做到的呢?接下来我们学习一下vue项目的开发流程。
对于vue项目,index.html文件默认是引入了入口函数main.js文件,我们找到src/main.js文件,其代码如下:
1
2
3
4
5
6
7
8
9
10
11import Vue from 'vue'
import App from './App.vue'
import router from './router'
Vue.config.productionTip = false
new Vue({
router,
render: h => h(App)
}).$mount('#app')
// 调用mount函数相当于直接给定el属性。上述代码中,包括如下几个关键点:
- import: 导入指定文件,并且重新起名。例如上述代码
import App from './App.vue'导入当前目录下得App.vue并且起名为App - new Vue(): 创建vue对象
- $mount(‘#app’);将vue对象创建的dom对象挂在到id=app的这个标签区域中,作用和之前学习的vue对象的el属性一致。
- router: 路由,详细在后面的小节讲解
- render: 主要使用视图的渲染的。基于App中定义的视图,创建出虚拟的dom元素,到index.html的#app区域。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
<html lang="">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<link rel="icon" href="<%= BASE_URL %>favicon.ico">
<title><%= htmlWebpackPlugin.options.title %></title>
</head>
<body>
<noscript>
<strong>We're sorry but <%= htmlWebpackPlugin.options.title %> doesn't work properly without JavaScript enabled. Please enable it to continue.</strong>
</noscript>
<div id="app"></div>
<!-- built files will be auto injected -->
</body>
</html>那么这个App对象怎么回事呢,我们打开App.vue,注意的是.vue结尾的都是vue组件。而vue的组件文件包含3个部分:
- template: 模板部分,主要是HTML代码,用来展示页面主体结构的
- script: js代码区域,主要是通过js代码来控制模板的数据来源和行为的
- style: css样式部分,主要通过css样式控制模板的页面效果的
这个时候我们发现。App.vue里面也有一个id为app的div,会不会和外面的app冲突了呀。这个是不会的,vue文件里面的id只和本vue文件的css或者js相对应。
接下来我们可以简化模板部分内容,添加script部分的数据模型,删除css样式,完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<template>
<div id="app">
{{message}}
</div>
</template>
<script>
export default {
// 数据模型
data(){
return {
"message":"hello world"
}
}
}
</script>
<style>
</style>工程总结
首先需要一个main.js:
1
2
3
4
5
6
7
8
9
10
11
12
13
14import Vue from 'vue'
import App from './App.vue'
import router from './router'
//引入ElementUI组件
import ElementUI from 'element-ui';
import 'element-ui/lib/theme-chalk/index.css';
Vue.config.productionTip = false
Vue.use(ElementUI);
new Vue({
router,
render: h => h(App)
}).$mount("#app")然后定义一个App.vue文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<template>
<div>
<router-view></router-view>
</div>
</template>
<script>
export default {
components: { },
data() {
return {
}
},
methods: {
}
}
</script>
<style>
</style>然后再router里面规定好router.js然后把不同的路径引向不同的Vue组件即可。
Element
Element:是饿了么公司前端开发团队提供的一套基于 Vue 的网站组件库,用于快速构建网页。
Element 提供了很多组件(组成网页的部件)供我们使用。例如 超链接、按钮、图片、表格等等。如下图所示就是我们开发的页面和ElementUI提供的效果对比:可以发现ElementUI提供的各式各样好看的按钮。
快速入门
在命令行输入如下命令可以安装element:
1
npm install element-ui@2.15.3
然后我们需要在main.js这个入口js文件中引入ElementUI的组件库,其代码如下:
1
2
3
4import ElementUI from 'element-ui';
import 'element-ui/lib/theme-chalk/index.css';
Vue.use(ElementUI);然后我们需要按照vue项目的开发规范,在src/views目录下创建一个vue组件文件,注意组件名称后缀是.vue,并且在组件文件中编写之前介绍过的基本组件语法,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22<template>
<div>
<el-row>
<el-button>默认按钮</el-button>
<el-button type="primary">主要按钮</el-button>
<el-button type="success">成功按钮</el-button>
<el-button type="info">信息按钮</el-button>
<el-button type="warning">警告按钮</el-button>
<el-button type="danger">危险按钮</el-button>
</el-row>
</div>
</template>
<script>
export default {
}
</script>
<style>
</style>然后再App.vue里做这样的修改就好:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<template>
<div>
<element-view></element-view>
</div>
</template>
<script>
import ElementView from './views/ElementView.vue'
export default {
components: {ElementView},
data(){
return{
}
},
method: {
}
}
</script>
<style>
</style>其中component代表引入组件。组件的名字叫做AbcdefgHijklmn,那么在template里面叫AbcdefgHijklmn也可以,叫abcdefg-hijklmn都可以
ElementUI是如何将数据模型绑定到视图的呢?可以在Element UI的官网中进行参数的查找。
带事件函数的Element UI
复制代码到我们的ElementView.vue组件文件的template中,拷贝如下代码:
1
2
3
4
5<el-pagination
background
layout="prev, pager, next"
:total="1000">
</el-pagination>这样就可以有一个很不错的分页组件。
对于分页组件我们需要关注的是如下几个重要属性(可以通过查阅官网组件中最下面的组件属性详细说明得到):
- background: 添加北京颜色,也就是上图蓝色背景色效果。
- layout: 分页工具条的布局,其具体值包含
sizes,prev,pager,next,jumper,->,total,slot这些值 - total: 数据的总数量
对于分页组件,除了上述几个属性,还有2个非常重要的事件我们需要去学习:
- size-change : pageSize 改变时会触发
- current-change :currentPage 改变时会触发
如果需要使用这两个属性,需要变成:
此时Panigation组件的template完整代码如下:
1
2
3
4
5
6
7
8<!-- Pagination分页 -->
<el-pagination
@size-change="handleSizeChange"
@current-change="handleCurrentChange"
background
layout="sizes,prev, pager, next,jumper,total"
:total="1000">
</el-pagination>然后在method()域处理这个函数。
Element UI的插槽
1
2
3<template slot-scope="scope">
<img :src="scope.row.image" width="100px" height="70px">
</template>scope.row是当前行的信息
路由
而我们vue官方提供了路由插件Vue Router,其主要组成如下:
- VueRouter:路由器类,根据路由请求在路由视图中动态渲染选中的组件
- <router-link>:请求链接组件,浏览器会解析成<a>
- <router-view>:动态视图组件,用来渲染展示与路由路径对应的组件
首先VueRouter根据我们配置的url的hash片段和路由的组件关系去维护一张路由表;
然后我们页面提供一个<router-link>组件,用户点击,发出路由请求;
接着我们的VueRouter根据路由请求,在路由表中找到对应的vue组件;
最后VueRouter会切换<router-view>中的组件,从而进行视图的更新
那要如何使用router呢?
- 首先需要安装vue-router
- 定义路由:
router/index.js
1
2
3
4
5
6
7
8
9
10
11
12
13{
path: '/',
name: 'home',
component: HomeView
},
{
path: '/about',
name: 'about',
// route level code-splitting
// this generates a separate chunk (about.[hash].js) for this route
// which is lazy-loaded when the route is visited.
component: () => import(/* webpackChunkName: "about" */ '../views/AboutView.vue')
}上面是一个实例,应该很好懂,每一个项目对应了一个路由映射。
路由基本信息配置好了,路由表已经被加载,此时我们还缺少2个东西,就是<router-lin>和<router-view>,所以我们需要修改2个页面(EmpView.vue和DeptView.vue)我们左侧栏的2个按钮为router-link,其代码如下:
1
2
3
4
5
6<el-menu-item index="1-1">
<router-link to="/dept">部门管理</router-link>
</el-menu-item>
<el-menu-item index="1-2">
<router-link to="/emp">员工管理</router-link>
</el-menu-item>然后我们还需要在内容展示区域即App.vue中定义route-view,作为组件的切换,其App.vue的完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25<template>
<div id="app">
<!-- {{message}} -->
<!-- <element-view></element-view> -->
<!-- <emp-view></emp-view> -->
<router-view></router-view>
</div>
</template>
<script>
// import EmpView './views/tlias/EmpView.vue'
// import ElementView './views/Element/ElementView.vue'
export default {
components: { },
data(){
return {
"message":"hello world"
}
}
}
</script>
<style>
</style>但是我们浏览器打开地址: http://localhost:7000/ ,发现一片空白,因为我们默认的路由路径是/,但是路由配置中没有对应的关系,
所以我们需要在路由配置中/对应的路由组件,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16const routes = [
{
path: '/emp',
name: 'emp',
component: () => import('../views/tlias/EmpView.vue')
},
{
path: '/dept',
name: 'dept',
component: () => import('../views/tlias/DeptView.vue')
},
{
path: '/',
redirect:'/emp' //表示重定向到/emp即可
},
]打包部署
我们的前端工程开发好了,但是我们需要发布,那么如何发布呢?主要分为2步:
- 前端工程打包(npm build),然后会在工程目录下生成一个dist目录,用于存放需要发布的前端资源。
- 通过nginx服务器发布前端工程。将dist目录下面的所有元素拷贝到nginx的html目录下即可。如果80端口被占用,我们需要通过conf/nginx.conf配置文件来修改端口号。如下图所示:
nginx: Nginx是一款轻量级的Web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其特点是占有内存少,并发能力强,在各大型互联网公司都有非常广泛的使用。
后端
Maven
Maven是Apache旗下的一个开源项目,是一款用于管理和构建java项目的工具。
Apache 软件基金会,成立于1999年7月,是目前世界上最大的最受欢迎的开源软件基金会,也是一个专门为支持开源项目而生的非盈利性组织。
使用Maven能够做什么呢?
- 依赖管理
- 统一项目结构
- 项目构建
依赖管理:
- 方便快捷的管理项目依赖的资源(jar包),避免版本冲突问题
当使用maven进行项目依赖(jar包)管理,则很方便的可以解决这个问题。 我们只需要在maven项目的pom.xml文件中,添加一段如下图所示的配置即可实现。
**统一项目结构 : **
- 提供标准、统一的项目结构
若我们创建的是一个maven工程,是可以帮我们自动生成统一、标准的项目目录结构:
目录说明:
- src/main/java: java源代码目录
- src/main/resources: 配置文件信息
- src/test/java: 测试代码
- src/test/resources: 测试配置文件信息
- pom.xml 依赖管理
项目构建 :
- maven提供了标准的、跨平台(Linux、Windows、MacOS) 的自动化项目构建方式
清理 编译 测试 打包 发布
快速入门
Maven模型
- 项目对象模型 (Project Object Model) 可以通过POM的描述信息来描述Maven工程(坐标)
- 依赖管理模型(Dependency) 指定了依赖的坐标
- 构建生命周期/阶段(Build lifecycle & phases) 通过提供的插件来完成项目的标准化构建
- 本地仓库:自己计算机上的一个目录(用来存储jar包)
- 中央仓库:由Maven团队维护的全球唯一的。仓库地址:https://repo1.maven.org/maven2/
- 远程仓库(私服):一般由公司团队搭建的私有仓库
依赖的查找:先找本地仓库,如果本地仓库没有,那就先从中央仓库把包下下来。
安装步骤
Maven安装配置步骤:
- 解压安装
- 配置仓库
- 配置Maven环境变量
1、解压 apache-maven-3.6.1-bin.zip(解压即安装)
建议解压到没有中文、特殊字符的路径下。如课程中解压到
E:\develop下。- bin目录 : 存放的是可执行命令。(mvn 命令重点关注)
- conf目录 :存放Maven的配置文件。(settings.xml配置文件后期需要修改)
- lib目录 :存放Maven依赖的jar包。(Maven也是使用java开发的,所以它也依赖其他的jar包)
2、配置本地仓库
2.1、在自己计算机上新一个目录(本地仓库,用来存储jar包)
2.2、进入到conf目录下修改settings.xml配置文件
1). 使用超级记事本软件,打开settings.xml文件,定位到53行
2). 复制
标签,粘贴到注释的外面(55行) 3). 复制之前新建的用来存储jar包的路径,替换掉
标签体内容 3、配置阿里云私服
由于中央仓库在国外,所以下载jar包速度可能比较慢,而阿里公司提供了一个远程仓库,里面基本也都有开源项目的jar包。
进入到conf目录下修改settings.xml配置文件:
1). 使用超级记事本软件,打开settings.xml文件,定位到160行左右
2). 在
标签下为其添加子标签 ,内容如下: 1
2
3
4
5
6<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>==注: 只可配置一个
(另一个要注释!) ,不然两个可能发生冲突,导致jar包无法下载!!!!!!!== 4、配置环境变量
Maven环境变量的配置类似于JDK环境变量配置一样
1). 在系统变量处新建一个变量MAVEN_HOME
- MAVEN_HOME环境变量的值,设置为maven的解压安装目录
2). 在Path中进行配置
- PATH环境变量的值,设置为:%MAVEN_HOME%\bin
3). 打开DOS命令提示符进行验证,出现如图所示表示安装成功
1
mvn -v
IDEA集成Maven
配置Maven环境
1、选择 IDEA中 File => Settings => Build,Execution,Deployment => Build Tools => Maven
2、设置IDEA使用本地安装的Maven,并修改配置文件及本地仓库路径
Maven home path :指定当前Maven的安装目录
User settings file :指定当前Maven的settings.xml配置文件的存放路径
Local repository :指定Maven的本地仓库的路径 (如果指定了settings.xml, 这个目录会自动读取出来, 可以不用手动指定)
3、配置工程的编译版本为11
- Maven默认使用的编译版本为5(版本过低)
创建Maven项目
1、创建一个空项目
2、创建模块,选择Maven,点击Next(如果是IDEA2023以后的,请选择Java-Maven,也就是说Maven环境在Java里)
3、填写模块名称,坐标信息,点击finish,创建完成(这个在Advance Setting里面设置)
4、在Maven工程下,创建HelloWorld类
Maven项目的目录结构:
maven-project01
|— src (源代码目录和测试代码目录)
|— main (源代码目录)
|— java (源代码java文件目录)
|— resources (源代码配置文件目录)
|— test (测试代码目录)
|— java (测试代码java目录)
|— resources (测试代码配置文件目录)
|— target (编译、打包生成文件存放目录)
POM配置详解
POM (Project Object Model) :指的是项目对象模型,用来描述当前的maven项目。
- 使用pom.xml文件来实现
pom.xml文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<!-- POM模型版本 -->
<modelVersion>4.0.0</modelVersion>
<!-- 当前项目坐标 -->
<groupId>com.itheima</groupId>
<artifactId>maven_project1</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 打包方式 -->
<packaging>jar</packaging>
</project>pom文件详解:
:pom文件的根标签,表示当前maven项目 :声明项目描述遵循哪一个POM模型版本 - 虽然模型本身的版本很少改变,但它仍然是必不可少的。目前POM模型版本是4.0.0
- 坐标 :
、 、 - 定位项目在本地仓库中的位置,由以上三个标签组成一个坐标
:maven项目的打包方式,通常设置为jar或war(默认值:jar)
什么是坐标?
- Maven中的坐标是==资源的唯一标识== , 通过该坐标可以唯一定位资源位置
- 使用坐标来定义项目或引入项目中需要的依赖
Maven坐标主要组成
- groupId:定义当前Maven项目隶属组织名称(通常是域名反写,例如:com.itheima)
- artifactId:定义当前Maven项目名称(通常是模块名称,例如 order-service、goods-service)
- version:定义当前项目版本号
注意:
- 上面所说的资源可以是插件、依赖、当前项目。
- 我们的项目如果被其他的项目依赖时,也是需要坐标来引入的。
导入Maven项目
- 方式1:使用Maven面板,快速导入项目
打开IDEA,选择右侧Maven面板,点击 + 号,选中对应项目的pom.xml文件,双击即可
说明:如果没有Maven面板,选择 View => Appearance => Tool Window Bars
- 方式2:使用idea导入模块项目
File => Project Structure => Modules => + => Import Module,找到要导入工程的pom.xml
找坐标:先找本地仓库中有没有这个包,再找Maven的本地中有没有导入这个Maven项目。再去私服或者中央仓库。
依赖管理
依赖配置
依赖:指当前项目运行所需要的jar包。一个项目中可以引入多个依赖:
例如:在当前工程中,我们需要用到logback来记录日志,此时就可以在maven工程的pom.xml文件中,引入logback的依赖。具体步骤如下:
在pom.xml中编写
标签 在
标签中使用 引入坐标 定义坐标的 groupId、artifactId、version
点击刷新按钮,引入最新加入的坐标(有个m加上一个循环符号的小按钮)
- 刷新依赖:保证每一次引入新的依赖,或者修改现有的依赖配置,都可以加入最新的坐标
注意事项:
- 如果引入的依赖,在本地仓库中不存在,将会连接远程仓库 / 中央仓库,然后下载依赖(这个过程会比较耗时,耐心等待)
- 如果不知道依赖的坐标信息,可以到mvn的中央仓库(https://mvnrepository.com/)中搜索
添加依赖的几种方式:
- 利用中央仓库搜索的依赖坐标
- 利用IDEA工具搜索依赖
- 熟练上手maven后,快速导入依赖
依赖传递
依赖传递可以分为:
直接依赖:在当前项目中通过依赖配置建立的依赖关系
间接依赖:被依赖的资源如果依赖其他资源,当前项目间接依赖其他资源
问题:之前我们讲了依赖具有传递性。那么A依赖B,B依赖C,如果A不想将C依赖进来,是否可以做到?
答案:在maven项目中,我们可以通过排除依赖来实现。
什么是排除依赖?
- 排除依赖:指主动断开依赖的资源。(被排除的资源无需指定版本)
1
2
3
4
5
6
7
8
9
10
11
12
13<dependency>
<groupId>com.itheima</groupId>
<artifactId>maven-projectB</artifactId>
<version>1.0-SNAPSHOT</version>
<!--排除依赖, 主动断开依赖的资源-->
<exclusions>
<exclusion>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</exclusion>
</exclusions>
</dependency>在一个dependency里面设置排除依赖!
依赖范围
在项目中导入依赖的jar包后,默认情况下,可以在任何地方使用。如果希望限制依赖的使用范围,可以通过
标签设置其作用范围。 主程序范围有效(main文件夹范围内)
测试程序范围有效(test文件夹范围内)
是否参与打包运行(package指令范围内)
scope标签的取值范围:
scope值 主程序 测试程序 打包(运行) 范例 compile(默认) Y Y Y log4j test - Y - junit provided Y Y - servlet-api runtime - Y Y jdbc驱动 生命周期
Maven的生命周期就是为了对所有的构建过程进行抽象和统一。 描述了一次项目构建,经历哪些阶段。
在Maven出现之前,项目构建的生命周期就已经存在,软件开发人员每天都在对项目进行清理,编译,测试及部署。虽然大家都在不停地做构建工作,但公司和公司间、项目和项目间,往往使用不同的方式做类似的工作。
Maven从大量项目和构建工具中学习和反思,然后总结了一套高度完美的,易扩展的项目构建生命周期。这个生命周期包含了项目的清理,初始化,编译,测试,打包,集成测试,验证,部署和站点生成等几乎所有构建步骤。
Maven对项目构建的生命周期划分为3套(相互独立):
clean:清理工作。
default:核心工作。如:编译、测试、打包、安装、部署等。
site:生成报告、发布站点等。
我们主要关注下面的几个阶段:
• clean:移除上一次构建生成的文件 clean
• compile:编译项目源代码 default
• test:使用合适的单元测试框架运行测试(junit) default
• package:将编译后的文件打包,如:jar、war等 default
• install:安装项目到本地仓库 default
Maven的生命周期是抽象的,这意味着生命周期本身不做任何实际工作。在Maven的设计中,实际任务(如源代码编译)都交由插件来完成。
生命周期的顺序是:clean –> validate –> compile –> test –> package –> verify –> install –> site –> deploy
我们需要关注的就是:clean –> compile –> test –> package –> install
说明:在同一套生命周期中,我们在执行后面的生命周期时,前面的生命周期都会执行。
思考:当运行package生命周期时,clean、compile生命周期会不会运行?
clean不会运行,compile会运行。 因为compile与package属于同一套生命周期,而clean与package不属于同一套生命周期。
在日常开发中,当我们要执行指定的生命周期时,有两种执行方式:
- 在idea工具右侧的maven工具栏中,选择对应的生命周期,双击执行
- 在DOS命令行中,通过maven命令执行
Springboot
Spring发展到今天已经形成了一种开发生态圈,Spring提供了若干个子项目,每个项目用于完成特定的功能。而我们在项目开发时,一般会偏向于选择这一套spring家族的技术,来解决对应领域的问题,那我们称这一套技术为spring全家桶。
而Spring家族旗下这么多的技术,最基础、最核心的是 SpringFramework。其他的spring家族的技术,都是基于SpringFramework的,SpringFramework中提供很多实用功能,如:依赖注入、事务管理、web开发支持、数据访问、消息服务等等。
而如果我们在项目中,直接基于SpringFramework进行开发,存在两个问题:配置繁琐、入门难度大。
所以基于此呢,spring官方推荐我们从另外一个项目开始学习,那就是目前最火爆的SpringBoot。
通过springboot就可以快速的帮我们构建应用程序,所以springboot呢,最大的特点有两个 :
- 简化配置
- 快速开发
Spring Boot 可以帮助我们非常快速的构建应用程序、简化开发、提高效率 。
入门
需求:基于SpringBoot的方式开发一个web应用,浏览器发起请求/hello后,给浏览器返回字符串 “Hello World ~”。
第1步:创建SpringBoot工程项目
基于Spring官方骨架,创建SpringBoot工程。
在IDEA里的new Project里面选择Springboot,Type选择Maven,Language选择Java。Artifact和Package name可以默认,SDK和Java可以默认
基本信息描述完毕之后,勾选web开发相关依赖。(Spring Web)
点击Finish之后,就会联网创建这个SpringBoot工程,创建好之后,会创建一个类,我们叫做启动类。不需要动。
第2步:定义HelloController类,添加请求处理方法hello,并添加注解(这个叫做请求处理类,我们叫做Controller)
- 创建一个子包controller(定义了所有请求处理类所在的包)
- 然后在controller包下新建一个类:HelloController
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16package sukunahust.demo.controller;
import org.springframework.web.bind.annotation.*;
// 请求处理类
public class HelloController {
public String hello(){
System.out.println("Hello World ~");
return "Hello World ~";
}
}第3步:测试运行
运行SpringBoot自动生成的启动类的main方法即可。
spring-boot-starter-web和spring-boot-starter-test,在SpringBoot中又称为:起步依赖
而在SpringBoot的项目中,有很多的起步依赖,他们有一个共同的特征:就是以
spring-boot-starter-作为开头。在以后大家遇到spring-boot-starter-xxx这类的依赖,都为起步依赖。起步依赖有什么特殊之处呢,这里我们以入门案例中引入的起步依赖做为讲解:
- spring-boot-starter-web:包含了web应用开发所需要的常见依赖
- spring-boot-starter-test:包含了单元测试所需要的常见依赖
spring-boot-starter-web内部把关于Web开发所有的依赖都已经导入并且指定了版本,只需引入
spring-boot-starter-web依赖就可以实现Web开发的需要的功能问题:为什么我们之前书写的SpringBoot入门程序中,并没有把程序部署到Tomcat的webapps目录下,也可以运行呢?
原因呢,是因为在我们的SpringBoot中,引入了web运行环境(也就是引入spring-boot-starter-web起步依赖),其内部已经集成了内置的Tomcat服务器。
我们可以通过IDEA开发工具右侧的maven面板中,就可以看到当前工程引入的依赖。其中已经将Tomcat的相关依赖传递下来了,也就是说在SpringBoot中可以直接使用Tomcat服务器。
HTTP协议
浏览器:
输入网址:
http://192.168.100.11:8080/hello通过IP地址192.168.100.11定位到网络上的一台计算机
我们之前在浏览器中输入的localhost,就是127.0.0.1(本机)
通过端口号8080找到计算机上运行的程序
localhost:8080, 意思是在本地计算机中找到正在运行的8080端口的程序/hello是请求资源位置
- 资源:对计算机而言资源就是数据
- web资源:通过网络可以访问到的资源(通常是指存放在服务器上的数据)
localhost:8080/hello,意思是向本地计算机中的8080端口程序,获取资源位置是/hello的数据- 8080端口程序,在服务器找/hello位置的资源数据,发给浏览器
- 资源:对计算机而言资源就是数据
服务器:(可以理解为ServerSocket)
- 接收到浏览器发送的信息(如:/hello)
- 在服务器上找到/hello的资源
- 把资源发送给浏览器
我们在JavaSE阶段学习网络编程时,有讲过网络三要素:
- IP :网络中计算机的唯一标识
- 端口 :计算机中运行程序的唯一标识
- 协议 :网络中计算机之间交互的规则
问题:浏览器和服务器两端进行数据交互,使用什么协议?
答案:http协议
概述
HTTP:Hyper Text Transfer Protocol(超文本传输协议),规定了浏览器与服务器之间数据传输的规则。
- http是互联网上应用最为广泛的一种网络协议
- http协议要求:浏览器在向服务器发送请求数据时,或是服务器在向浏览器发送响应数据时,都必须按照固定的格式进行数据传输
我们刚才初步认识了HTTP协议,那么我们在看看HTTP协议有哪些特点:
**基于TCP协议: ** 面向连接,安全
TCP是一种面向连接的(建立连接之前是需要经过三次握手)、可靠的、基于字节流的传输层通信协议,在数据传输方面更安全
基于请求-响应模型: 一次请求对应一次响应(先请求后响应)
请求和响应是一一对应关系,没有请求,就没有响应
HTTP协议是无状态协议: 对于数据没有记忆能力。每次请求-响应都是独立的
无状态指的是客户端发送HTTP请求给服务端之后,服务端根据请求响应数据,响应完后,不会记录任何信息。
- 缺点: 多次请求间不能共享数据
- 优点: 速度快
请求之间无法共享数据会引发的问题:
- 如:京东购物。加入购物车和去购物车结算是两次请求
- 由于HTTP协议的无状态特性,加入购物车请求响应结束后,并未记录加入购物车是何商品
- 发起去购物车结算的请求后,因为无法获取哪些商品加入了购物车,会导致此次请求无法正确展示数据
具体使用的时候,我们发现京东是可以正常展示数据的,原因是Java早已考虑到这个问题,并提出了使用会话技术(Cookie、Session)来解决这个问题。具体如何来做,我们后面课程中会讲到。
刚才提到HTTP协议是规定了请求和响应数据的格式,那具体的格式是什么呢?
浏览器和服务器是按照HTTP协议进行数据通信的。
HTTP协议又分为:请求协议和响应协议
- 请求协议:浏览器将数据以请求格式发送到服务器
- 包括:请求行、请求头 、请求体
- 响应协议:服务器将数据以响应格式返回给浏览器
- 包括:响应行 、响应头 、响应体
请求协议
在HTTP1.1版本中,浏览器访问服务器的几种方式:
请求方式 请求说明 GET 获取资源。
向特定的资源发出请求。例:http://www.baidu.com/s?wd=itheimaPOST 传输实体主体。
向指定资源提交数据进行处理请求(例:上传文件),数据被包含在请求体中。OPTIONS 返回服务器针对特定资源所支持的HTTP请求方式。
因为并不是所有的服务器都支持规定的方法,为了安全有些服务器可能会禁止掉一些方法,例如:DELETE、PUT等。那么OPTIONS就是用来询问服务器支持的方法。HEAD 获得报文首部。
HEAD方法类似GET方法,但是不同的是HEAD方法不要求返回数据。通常用于确认URI的有效性及资源更新时间等。PUT 传输文件。
PUT方法用来传输文件。类似FTP协议,文件内容包含在请求报文的实体中,然后请求保存到URL指定的服务器位置。DELETE 删除文件。
请求服务器删除Request-URI所标识的资源TRACE 追踪路径。
回显服务器收到的请求,主要用于测试或诊断CONNECT 要求用隧道协议连接代理。
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器在我们实际应用中常用的也就是 :GET、POST
GET方式的请求协议:
请求行 :HTTP请求中的第一行数据。由:
请求方式、资源路径、协议/版本组成(之间使用空格分隔)- 请求方式:GET
- 资源路径:/brand/findAll?name=OPPO&status=1
- 请求路径:/brand/findAll
- 请求参数:name=OPPO&status=1
- 请求参数是以key=value形式出现
- 多个请求参数之间使用
&连接
- 请求路径和请求参数之间使用
?连接
- 协议/版本:HTTP/1.1
请求头 :第二行开始,上图黄色部分内容就是请求头。格式为key: value形式
- http是个无状态的协议,所以在请求头设置浏览器的一些自身信息和想要响应的形式。这样服务器在收到信息后,就可以知道是谁,想干什么了
常见的HTTP请求头有:
1
2
3
4
5
6
7
8
9
10
11
12
13Host: 表示请求的主机名
User-Agent: 浏览器版本。 例如:Chrome浏览器的标识类似Mozilla/5.0 ...Chrome/79 ,IE浏览器的标识类似Mozilla/5.0 (Windows NT ...)like Gecko
Accept:表示浏览器能接收的资源类型,如text/*,image/*或者*/*表示所有;
Accept-Language:表示浏览器偏好的语言,服务器可以据此返回不同语言的网页;
Accept-Encoding:表示浏览器可以支持的压缩类型,例如gzip, deflate等。
Content-Type:请求主体的数据类型
Content-Length:数据主体的大小(单位:字节)
举例说明:服务端可以根据请求头中的内容来获取客户端的相关信息,有了这些信息服务端就可以处理不同的业务需求。
比如:
- 不同浏览器解析HTML和CSS标签的结果会有不一致,所以就会导致相同的代码在不同的浏览器会出现不同的效果
- 服务端根据客户端请求头中的数据获取到客户端的浏览器类型,就可以根据不同的浏览器设置不同的代码来达到一致的效果(这就是我们常说的浏览器兼容问题)
- 请求体 :存储请求参数
- GET请求的请求参数在请求行中,故不需要设置请求体
POST方式的请求协议:
- 请求行(以上图中红色部分):包含请求方式、资源路径、协议/版本
- 请求方式:POST
- 资源路径:/brand
- 协议/版本:HTTP/1.1
- 请求头(以上图中黄色部分)
- 请求体(以上图中绿色部分) :存储请求参数
- 请求体和请求头之间是有一个空行隔开(作用:用于标记请求头结束)
GET请求和POST请求的区别:
区别方式 GET请求 POST请求 请求参数 请求参数在请求行中。
例:/brand/findAll?name=OPPO&status=1请求参数在请求体中 请求参数长度 请求参数长度有限制(浏览器不同限制也不同) 请求参数长度没有限制 安全性 安全性低。原因:请求参数暴露在浏览器地址栏中。 安全性相对高 更详细的请求区别可以看sukuna写的计网八股。
响应协议
与HTTP的请求一样,HTTP响应的数据也分为3部分:响应行、响应头 、响应体

响应行(以上图中红色部分):响应数据的第一行。响应行由
协议及版本、响应状态码、状态码描述组成- 协议/版本:HTTP/1.1
- 响应状态码:200
- 状态码描述:OK
响应头(以上图中黄色部分):响应数据的第二行开始。格式为key:value形式
- http是个无状态的协议,所以可以在请求头和响应头中设置一些信息和想要执行的动作,这样,对方在收到信息后,就可以知道你是谁,你想干什么
常见的HTTP响应头有:
1
2
3
4
5
6
7
8
9Content-Type:表示该响应内容的类型,例如text/html,image/jpeg ;
Content-Length:表示该响应内容的长度(字节数);
Content-Encoding:表示该响应压缩算法,例如gzip ;
Cache-Control:指示客户端应如何缓存,例如max-age=300表示可以最多缓存300秒 ;
Set-Cookie: 告诉浏览器为当前页面所在的域设置cookie ;
- 响应体(以上图中绿色部分): 响应数据的最后一部分。存储响应的数据
- 响应体和响应头之间有一个空行隔开(作用:用于标记响应头结束)
状态码分类 说明 1xx 响应中 — 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 2xx 成功 — 表示请求已经被成功接收,处理已完成 3xx 重定向 — 重定向到其它地方,让客户端再发起一个请求以完成整个处理 4xx 客户端错误 — 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 5xx 服务器端错误 — 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 参考: 资料/SpringbootWeb/响应状态码.md
关于响应状态码,我们先主要认识三个状态码,其余的等后期用到了再去掌握:
- 200 ok 客户端请求成功
- 404 Not Found 请求资源不存在
- 500 Internal Server Error 服务端发生不可预期的错误
Web服务器
服务器,也称伺服器。是提供计算服务的设备。由于服务器需要响应服务请求,并进行处理,因此一般来说服务器应具备承担服务并且保障服务的能力。
服务器的构成包括处理器、硬盘、内存、系统总线等,和通用的计算机架构类似,但是由于需要提供高可靠的服务,因此在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面要求较高。
在网络环境下,根据服务器提供的服务类型不同,可分为:文件服务器,数据库服务器,应用程序服务器,WEB服务器等。
服务器只是一台设备,必须安装服务器软件才能提供相应的服务。
服务器软件
服务器软件:基于ServerSocket编写的程序
- 服务器软件本质是一个运行在服务器设备上的应用程序
- 能够接收客户端请求,并根据请求给客户端响应数据
Web服务器是一个应用程序(软件),对HTTP协议的操作进行封装,使得程序员不必直接对协议进行操作(不用程序员自己写代码去解析http协议规则),让Web开发更加便捷。主要功能是”提供网上信息浏览服务”。
eb服务器是安装在服务器端的一款软件,将来我们把自己写的Web项目部署到Tomcat服务器软件中,当Web服务器软件启动后,部署在Web服务器软件中的页面就可以直接通过浏览器来访问了。
Web服务器软件使用步骤
- 准备静态资源
- 下载安装Web服务器软件
- 将静态资源部署到Web服务器上
- 启动Web服务器使用浏览器访问对应的资源
基于SpringBoot的方式开发一个web应用,浏览器发起请求 /hello 后 ,给浏览器返回字符串 “Hello World ~”。
其实呢,是我们在浏览器发起请求,请求了我们的后端web服务器(也就是内置的Tomcat)。而我们在开发web程序时呢,定义了一个控制器类Controller,请求会被部署在Tomcat中的Controller接收,然后Controller再给浏览器一个响应,响应一个字符串 “Hello World”。 而在请求响应的过程中是遵循HTTP协议的。
但是呢,这里要告诉大家的时,其实在Tomcat这类Web服务器中,是不识别我们自己定义的Controller的。但是我们前面讲到过Tomcat是一个Servlet容器,是支持Serlvet规范的,所以呢,在tomcat中是可以识别 Servlet程序的。 那我们所编写的XxxController 是如何处理请求的,又与Servlet之间有什么联系呢?
其实呢,在SpringBoot进行web程序开发时,它内置了一个核心的Servlet程序 DispatcherServlet,称之为 核心控制器。 DispatcherServlet 负责接收页面发送的请求,然后根据执行的规则,将请求再转发给后面的请求处理器Controller,请求处理器处理完请求之后,最终再由DispatcherServlet给浏览器响应数据。
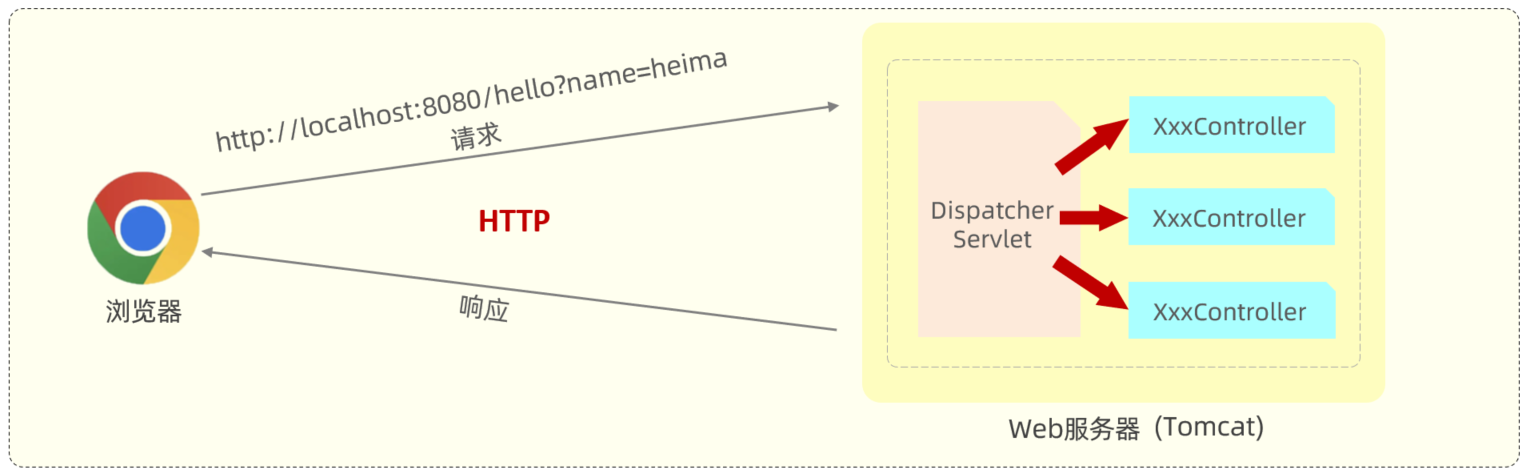
那将来浏览器发送请求,会携带请求数据,包括:请求行、请求头;请求到达tomcat之后,tomcat会负责解析这些请求数据,然后呢将解析后的请求数据会传递给Servlet程序的HttpServletRequest对象,那也就意味着 HttpServletRequest 对象就可以获取到请求数据。 而Tomcat,还给Servlet程序传递了一个参数 HttpServletResponse,通过这个对象,我们就可以给浏览器设置响应数据.
请求
简单参数
简单参数:在向服务器发起请求时,向服务器传递的是一些普通的请求数据。比如说
hello/name=Tom&age=10在Springboot的环境中,对原始的API进行了封装,接收参数的形式更加简单。 如果是简单参数,参数名与形参变量名相同,定义同名的形参即可接收参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
public class RequestController {
// http://localhost:8080/simpleParam?name=Tom&age=10
// 第1个请求参数: name=Tom 参数名:name,参数值:Tom
// 第2个请求参数: age=10 参数名:age , 参数值:10
//springboot方式
public String simpleParam(String name , Integer age ){//形参名和请求参数名保持一致
System.out.println(name+" : "+age);
return "OK";
}
}直接可以把参数写在函数的形参中。然后会自动发生类型的变化。
如果方法形参名称与请求参数名称不一致,controller方法中的形参还能接收到请求参数值吗?当然是不能的。
解决方案:可以使用Spring提供的@RequestParam注解完成映射
在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
public class RequestController {
// http://localhost:8080/simpleParam?name=Tom&age=20
// 请求参数名:name
//springboot方式
public String simpleParam( String username , Integer age ){
System.out.println(username+" : "+age);
return "OK";
}
}@RequestParam中的required属性默认为true(默认值也是true),代表该请求参数必须传递,如果不传递将报错。当然也可以改成false
实体参数
在使用简单参数做为数据传递方式时,前端传递了多少个请求参数,后端controller方法中的形参就要书写多少个。如果请求参数比较多,通过上述的方式一个参数一个参数的接收,会比较繁琐。
此时,我们可以考虑将请求参数封装到一个实体类对象中。 要想完成数据封装,需要遵守如下规则:请求参数名与实体类的属性名相同
定义下面的实体类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class User {
private String name;
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}Controller方法:
1
2
3
4
5
6
7
8
9
public class RequestController {
//实体参数:简单实体对象
public String simplePojo(User user){
System.out.println(user);
return "OK";
}
}那么含有name和age两个参数的请求就可以被处理了!请求的值会被封装到自己定义好的类中。(注意:自己定义的实体类get和set一定要都定义好!!)
当然,实体类的封装也是可以嵌套封装的,比如说实体类的属性可以是另外一个实体类。
复杂实体对象的封装,需要遵守如下规则:
请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。然后前端传递参数的时候要用
.来表示层次关系。数组集合参数
数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数比如说
hobby = Java & hobby = game或者hobby = Java,game后端程序接收上述多个值的方式有两种:
- 数组
- 集合
首先是数组接受,就是将函数的形参定义成数组即可。比如说String[] 请求参数名
Controller方法:
1
2
3
4
5
6
7
8
9
10
public class RequestController {
//数组集合参数
// hobby = Java & hobby = game
public String arrayParam(String[] hobby){
System.out.println(Arrays.toString(hobby));
return "OK";
}
}下面是用Java的List来进行接收:
Controller方法:
1
2
3
4
5
6
7
8
9
public class RequestController {
//数组集合参数
public String listParam( List<String> hobby){
System.out.println(hobby);
return "OK";
}
}日期参数
因为日期的格式多种多样(如:2022-12-12 10:05:45 、2022/12/12 10:05:45),那么对于日期类型的参数在进行封装的时候,需要通过@DateTimeFormat注解,以及其pattern属性来设置日期的格式。
- @DateTimeFormat注解的pattern属性中指定了哪种日期格式,前端的日期参数就必须按照指定的格式传递。
- 后端controller方法中,需要使用Date类型或LocalDateTime类型,来封装传递的参数。
Controller方法:
1
2
3
4
5
6
7
8
9
public class RequestController {
//日期时间参数
public String dateParam( LocalDateTime updateTime){
System.out.println(updateTime);
return "OK";
}
}这个形参的名称自然也是要和请求参数一致。
JSON格式参数
服务端Controller方法接收JSON格式数据:
- 传递json格式的参数,在Controller中会使用实体类进行封装。
- 封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。
接受json格式需要定义实例类。在json的定义中json可能会有嵌套,那么在实例类中的属性也需要设置为另外一个实例类!(键名需要和实体对象的属性名保持一致)
如果json是这样的:
1
2
3
4
5
6
7
8{
name: "Sukuna",
age = "24",
address: {
province: "Hubei",
city: "Wuhan"
}
}那就要这样接受json定义的数据。
实体类:Address
1
2
3
4
5
6public class Address {
private String province;
private String city;
//省略GET , SET 方法
}实体类:User
1
2
3
4
5
6
7public class User {
private String name;
private Integer age;
private Address address;
//省略GET , SET 方法
}Controller方法:
1
2
3
4
5
6
7
8
9
public class RequestController {
//JSON参数
public String jsonParam( User user){
System.out.println(user);
return "OK";
}
}路径参数
在现在的开发中,经常还会直接在请求的URL中传递参数。例如:
1
2http://localhost:8080/user/1
http://localhost:880/user/1/0上述的这种传递请求参数的形式呢,我们称之为:路径参数。
学习路径参数呢,主要掌握在后端的controller方法中,如何接收路径参数。
路径参数:
- 前端:通过请求URL直接传递参数
- 后端:使用{…}来标识该路径参数,需要使用@PathVariable获取路径参数
使用一个通配符来进行参数的获取。
Controller方法:
1
2
3
4
5
6
7
8
9
public class RequestController {
//路径参数
public String pathParam( Integer id){
System.out.println(id);
return "OK";
}
}响应
@ResponseBody
@ResponseBody注解:
- 类型:方法注解、类注解(如果注解在类上,这个类里面的所有的方法都会被这样注解)
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
@RestController注解,是一个组合注解。
- @RestController = @Controller + @ResponseBody
结论:在类上添加@RestController就相当于添加了@ResponseBody注解。
- 类上有@RestController注解或@ResponseBody注解时:表示当前类下所有的方法返回值做为响应数据
- 方法的返回值,如果是一个POJO对象或集合时,会先转换为JSON格式,在响应给浏览器
没有加上注解@ResponseBody或者@RestController将返回值设置为JSON格式,不然会自动认为你返回的是一个页面。
在@Controller注解中,返回的是字符串,或者是字符串匹配的模板名称,即直接渲染视图,与html页面配合使用的,在这种情况下,前后端的配合要求比较高,java后端的代码要结合html的情况进行渲染,使用model对象(或者modelandview)的数据将填充user视图中的相关属性,然后展示到浏览器,这个过程也可以称为渲染
而在@restcontroller中,返回的应该是一个对象,即return一个user对象,这时,在没有页面的情况下,也能看到返回的是一个user对象对应的json字符串,而前端的作用是利用返回的json进行解析渲染页面,java后端的代码比较自由。
响应的数据就是这个方法的返回值。
- 如果返回值是字符串,整数,浮点数之类的,那就返回对应的字符串。
- 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器。
统一的响应结果
如果我们开发一个大型项目,项目中controller方法将成千上万,使用上述方式将造成整个项目难以维护。那在真实的项目开发中是什么样子的呢?
在真实的项目开发中,无论是哪种方法,我们都会定义一个统一的返回结果。方案如下:
统一的返回结果使用类来描述,在这个结果中包含:
响应状态码:当前请求是成功,还是失败(Integer)
状态码信息:给页面的提示信息(String)
返回的数据:给前端响应的数据(字符串、对象、集合)(Object)
分层解耦
分层
在我们进行程序设计以及程序开发时,尽可能让每一个接口、类、方法的职责更单一些(单一职责原则)。
单一职责原则:一个类或一个方法,就只做一件事情,只管一块功能。
这样就可以让类、接口、方法的复杂度更低,可读性更强,扩展性更好,也更利用后期的维护。
那其实我们上述案例的处理逻辑呢,从组成上看可以分为三个部分:
- Controller:控制层。接收前端发送的请求,对请求进行处理,并响应数据。
- Service:业务逻辑层。处理具体的业务逻辑。
- Dao:数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、删、改、查。
基于三层架构的程序执行流程:
- 前端发起的请求,由Controller层接收(Controller响应数据给前端)
- Controller层调用Service层来进行逻辑处理(Service层处理完后,把处理结果返回给Controller层)
- Serivce层调用Dao层(逻辑处理过程中需要用到的一些数据要从Dao层获取)
- Dao层操作文件中的数据(Dao拿到的数据会返回给Service层)
思考:按照三层架构的思想,如何要对业务逻辑(Service层)进行变更,会影响到Controller层和Dao层吗?
答案:不会影响。 (程序的扩展性、维护性变得更好了)
控制层:接收前端发送的请求,对请求进行处理,并响应数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class EmpController {
//业务层对象
private EmpService empService = new EmpServiceA();
public Result list(){
//1. 调用service层, 获取数据
List<Emp> empList = empService.listEmp();
//3. 响应数据
return Result.success(empList);
}
}业务逻辑层:处理具体的业务逻辑
- 业务接口
1
2
3
4
5//业务逻辑接口(制定业务标准)
public interface EmpService {
//获取员工列表
public List<Emp> listEmp();
}- 业务实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33//业务逻辑实现类(按照业务标准实现)
public class EmpServiceA implements EmpService {
//dao层对象
private EmpDao empDao = new EmpDaoA();
public List<Emp> listEmp() {
//1. 调用dao, 获取数据
List<Emp> empList = empDao.listEmp();
//2. 对数据进行转换处理 - gender, job
empList.stream().forEach(emp -> {
//处理 gender 1: 男, 2: 女
String gender = emp.getGender();
if("1".equals(gender)){
emp.setGender("男");
}else if("2".equals(gender)){
emp.setGender("女");
}
//处理job - 1: 讲师, 2: 班主任 , 3: 就业指导
String job = emp.getJob();
if("1".equals(job)){
emp.setJob("讲师");
}else if("2".equals(job)){
emp.setJob("班主任");
}else if("3".equals(job)){
emp.setJob("就业指导");
}
});
return empList;
}
}数据访问层:负责数据的访问操作,包含数据的增、删、改、查
为什么要用接口?因为Dao的实现可以有很多种,定义接口可以将不同的实现方式进行统一。
- 数据访问接口
1
2
3
4
5//数据访问层接口(制定标准)
public interface EmpDao {
//获取员工列表数据
public List<Emp> listEmp();
}- 数据访问实现类
1
2
3
4
5
6
7
8
9
10
11//数据访问实现类
public class EmpDaoA implements EmpDao {
public List<Emp> listEmp() {
//1. 加载并解析emp.xml
String file = this.getClass().getClassLoader().getResource("emp.xml").getFile();
System.out.println(file);
List<Emp> empList = XmlParserUtils.parse(file, Emp.class);
return empList;
}
}解耦
首先需要了解软件开发涉及到的两个概念:内聚和耦合。
内聚:软件中各个功能模块内部的功能联系。
耦合:衡量软件中各个层/模块之间的依赖、关联的程度。
软件设计原则:高内聚低耦合。
高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 “高内聚”。
低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。
之前我们在编写代码时,需要什么对象,就直接new一个就可以了。 这种做法呢,层与层之间代码就耦合了,当service层的实现变了之后, 我们还需要修改controller层的代码。解决思路是:
- 提供一个容器,容器中存储一些对象(例:EmpService对象)
- controller程序从容器中获取EmpService类型的对象
我们想要实现上述解耦操作,就涉及到Spring中的两个核心概念:
控制反转: Inversion Of Control,简称IOC。对象的创建控制权由程序自身转移到外部(容器),这种思想称为控制反转。
对象的创建权由程序员主动创建转移到容器(由容器创建、管理对象)。这个容器称为:IOC容器或Spring容器
依赖注入: Dependency Injection,简称DI。容器为应用程序提供运行时,所依赖的资源,称之为依赖注入。
程序运行时需要某个资源,此时容器就为其提供这个资源。
例:EmpController程序运行时需要EmpService对象,Spring容器就为其提供并注入EmpService对象
IOC容器中创建、管理的对象,称之为:bean对象。
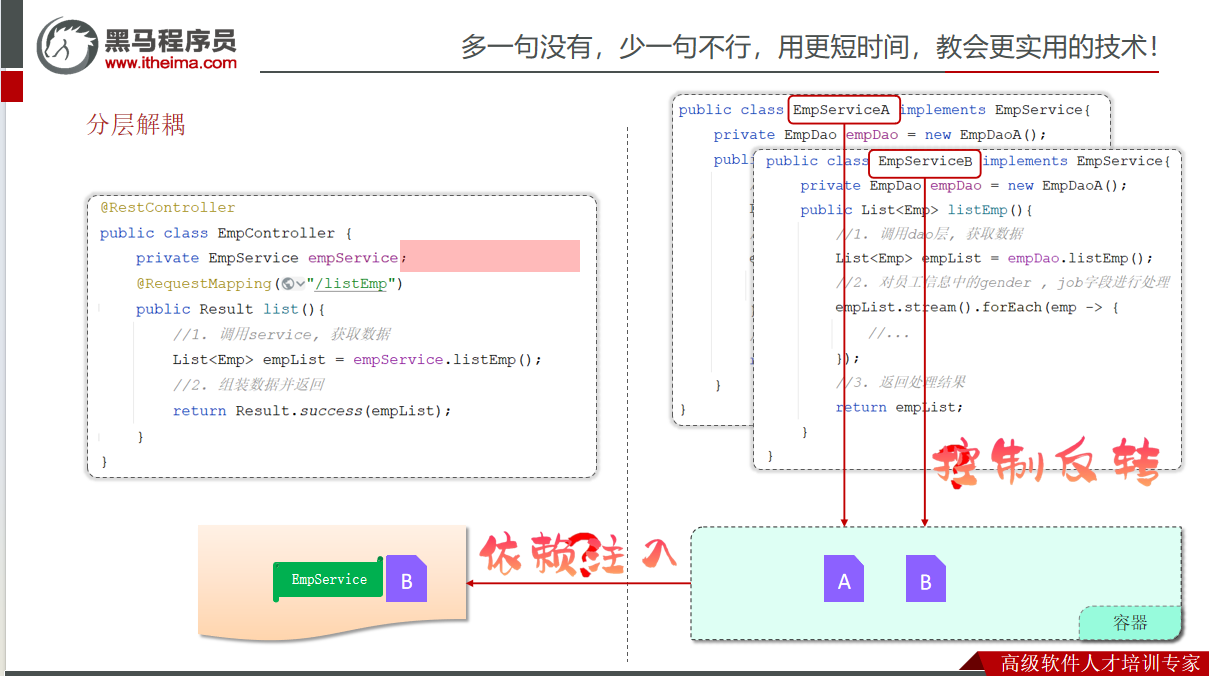
IOC&DI入门
1.Service层及Dao层的实现类,交给IOC容器管理
- 使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理
2.为Controller及Service注入运行时依赖的对象
- 使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象
IOC详解
在之前的入门案例中,要把某个对象交给IOC容器管理,需要在类上添加一个注解:@Component
而Spring框架为了更好的标识web应用程序开发当中,bean对象到底归属于哪一层,又提供了@Component的衍生注解:
注解 说明 位置 @Controller @Component的衍生注解 标注在控制器类上 @Service @Component的衍生注解 标注在业务类上 @Repository @Component的衍生注解 标注在数据访问类上(由于与mybatis整合,用的少) @Component 声明bean的基础注解 不属于以上三类时,用此注解 注意事项:
- 声明bean的时候,可以通过value属性指定bean的名字,如果没有指定,默认为类名首字母小写。
- 使用以上四个注解都可以声明bean,但是在springboot集成web开发中,声明控制器bean只能用@Controller。
问题:使用前面学习的四个注解声明的bean,一定会生效吗?
答案:不一定。(原因:bean想要生效,还需要被组件扫描)
使用四大注解声明的bean,要想生效,还需要被组件扫描注解@ComponentScan扫描。
@ComponentScan注解虽然没有显式配置,但是实际上已经包含在了引导类声明注解 @SpringBootApplication 中,==默认扫描的范围是SpringBoot启动类所在包及其子包==。
解决方案:手动添加@ComponentScan注解,指定要扫描的包 (==仅做了解,不推荐==)还是老老实实按照规范定义包即可。
DI详解
依赖注入,是指IOC容器要为应用程序去提供运行时所依赖的资源,而资源指的就是对象。
在入门程序案例中,我们使用了@Autowired这个注解,完成了依赖注入的操作,而这个Autowired翻译过来叫:自动装配。
@Autowired注解,默认是按照类型进行自动装配的(去IOC容器中找某个类型的对象,然后完成注入操作)
那如果在IOC容器中,存在多个相同类型的bean对象,会出现什么情况呢?这个会报错!
如何解决上述问题呢?Spring提供了以下几种解决方案:
@Primary
@Qualifier
@Resource
使用@Primary注解:当存在多个相同类型的Bean注入时,加上@Primary注解,来确定默认的实现。
使用@Qualifier注解:指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。(注意首字母小写!)
- @Qualifier注解不能单独使用,必须配合@Autowired使用
使用@Resource注解:是按照bean的名称进行注入。通过name属性指定要注入的bean的名称。
面试题 : @Autowird 与 @Resource的区别
- @Autowired 是spring框架提供的注解,而@Resource是JDK提供的注解
- @Autowired 默认是按照类型注入,而@Resource是按照名称注入
MySQL
MySQL配置
- 下载MySQL
- 配置环境变量(添加MySQL安装路径/bin到Path环境变量里)
- 初始化MySQL:
mysqld --initialize-insecure(生成data文件夹) - 注册MySQL服务
mysqld -install - 启动(停止)MySQL服务:
1
2net start mysql // 启动mysql服务
net stop mysql // 停止mysql服务- 修改默认账号密码:
mysqladmin -u root password XXX - 登录Mysql:
mysql -u用户名 -p密码
DDL
DML
DQL
多表设计查询
事务
索引
MyBatis
我们做为后端程序开发人员,通常会使用Java程序来完成对数据库的操作。Java程序操作数据库,现在主流的方式是:Mybatis。
什么是MyBatis?
MyBatis是一款优秀的 持久层(Dao) 框架,用于简化JDBC的开发。
MyBatis本是 Apache的一个开源项目iBatis,2010年这个项目由apache迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。
现在使用Mybatis操作数据库,就是在Mybatis中编写SQL查询代码,发送给数据库执行,数据库执行后返回结果。
Mybatis会把数据库执行的查询结果,使用实体类封装起来(一行记录对应一个实体类对象)
快速入门
Mybatis操作数据库的步骤:
准备工作(创建springboot工程、数据库表user、实体类User)
引入Mybatis的相关依赖,配置Mybatis(数据库连接信息)
编写SQL语句(注解/XML)
在pom.xml引入Mysql和Mybatis依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<!-- 仅供参考:只粘贴了pom.xml中部分内容 -->
<dependencies>
<!-- mybatis起步依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.3.0</version>
</dependency>
<!-- mysql驱动包依赖 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!-- spring单元测试 (集成了junit) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>(也可以在IDEA里面进行设置,在SQL->Mybatis Framework -> MySQL Driver)
连接数据库的四大参数:
- MySQL驱动类
- 登录名
- 密码
- 数据库连接字符串
基于上述分析,在Mybatis中要连接数据库,同样也需要以上4个参数配置。
在springboot项目中,可以编写application.properties文件,配置数据库连接信息。我们要连接数据库,就需要配置数据库连接的基本信息,包括:driver-class-name、url 、username,password。
application.properties:
1
2
3
4
5
6
7
8
9#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
# jdbc, url, database name
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=1234在创建出来的springboot工程中,在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper ,这是一个持久层接口(Mybatis的持久层接口规范一般都叫 XxxMapper)。
UserMapper:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import com.itheima.pojo.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper {
//查询所有用户数据
public List<User> list();
// 每一条查询的结果都是一个User(要对齐,数据库属性和User属性要一致),行之间以List的形式进行组织。
}
// 框架底层会自动实现实现类@Mapper注解:表示是mybatis中的Mapper接口
- 程序运行时:框架会自动生成接口的实现类对象(代理对象),并给交Spring的IOC容器管理
@Select注解:代表的就是select查询,用于书写select查询语句
让IDEA显示关于SQL的提示
- 右键->Show Context Actions->Inject Luaguage->Mysql
- 然后再IDEA的database选项中配置链接数据库。
JDBC(跳过)
数据库连接池
没有使用数据库连接池:
- 客户端执行SQL语句:要先创建一个新的连接对象,然后执行SQL语句,SQL语句执行后又需要关闭连接对象从而释放资源,每次执行SQL时都需要创建连接、销毁链接,这种频繁的重复创建销毁的过程是比较耗费计算机的性能。
数据库连接池是个容器,负责分配、管理数据库连接(Connection)(和线程池很像)
- 程序在启动时,会在数据库连接池(容器)中,创建一定数量的Connection对象
允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
- 客户端在执行SQL时,先从连接池中获取一个Connection对象,然后在执行SQL语句,SQL语句执行完之后,释放Connection时就会把Connection对象归还给连接池(Connection对象可以复用)
释放空闲时间超过最大空闲时间的连接,来避免因为没有释放连接而引起的数据库连接遗漏
- 客户端获取到Connection对象了,但是Connection对象并没有去访问数据库(处于空闲),数据库连接池发现Connection对象的空闲时间 > 连接池中预设的最大空闲时间,此时数据库连接池就会自动释放掉这个连接对象
数据库连接池的好处:
- 资源重用
- 提升系统响应速度
- 避免数据库连接遗漏
常见的数据库连接池:
- C3P0
- DBCP
- Druid
- Hikari (springboot默认)
现在使用更多的是:Hikari、Druid (性能更优越)
lombok
Lombok是一个实用的Java类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的Java代码。
通过注解的形式自动生成构造器、getter/setter、equals、hashcode、toString等方法,并可以自动化生成日志变量,简化java开发、提高效率。
注解 作用 @Getter/@Setter 为所有的属性提供get/set方法 @ToString 会给类自动生成易阅读的 toString 方法 @EqualsAndHashCode 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 @Data 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) @NoArgsConstructor 为实体类生成无参的构造器方法 @AllArgsConstructor 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 基础操作
日志操作
在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果。具体操作如下:
打开application.properties文件
开启mybatis的日志,并指定输出到控制台
1
2#指定mybatis输出日志的位置, 输出控制台
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl删除
Mybatis有一个参数占位符#{},占位符对应的数据就会转化成调用函数的参数。
- 接口方法
1
2
3
4
5
6
7
8
9
10
11
12
public interface EmpMapper {
//在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句
/**
* 根据id删除数据
* @param id 用户id
*/
//使用#{key}方式获取方法中的参数值
public void delete(Integer id);
// 返回值可以改成int,返回值为0代表失败了
}预编译SQL
上面的SQL语句会变成
delete from emp where id = ?,这就是预编译的SQL,然后把函数的传入参数的值传递给?性能更高:预编译SQL,编译一次之后会将编译后的SQL语句缓存起来,后面再次执行这条语句时,不会再次编译。(只是输入的参数不同)
更安全(防止SQL注入):将敏感字进行转义,保障SQL的安全性。
在Mybatis中提供的参数占位符有两种:${…} 、#{…}
#{…}
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
- 使用时机:参数传递,都使用#{…}
${…}
- 拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题
- 使用时机:如果对表名、列表进行动态设置时使用
新增
同样的,可以使用之前的操作,进行占位,但是我们希望主键能够自动生成。
@Options(useGeneratedKeys = true,keyProperty = "id")设置主键。同样的,我们希望能够传递一个对象类。也可以使用上面的占位符进行操作。(注意要变成驼峰命名法:
create_time->createTime)。在做的时候会主键返回代码实现:
1
2
3
4
5
6
7
8
9
public interface EmpMapper {
//会自动将生成的主键值,赋值给emp对象的id属性
public void insert(Emp emp);
}更新
和之前一样,不过是改成了@Update
查询
和入门程序中的查询一样,查询方法的返回值是一个对象类,对象类的属性和数据库中表的属性是一致的。必须是一致的,长得一模一样的!
- 实体类属性名和数据库表查询返回的字段名一致,会自动封装。
- 实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。
解决方案:
- 起别名
- 结果映射
- 开启驼峰命名
起别名:在SQL语句中,对不一样的列名起别名,别名和实体类属性名一样。
手动结果映射:通过 @Results及@Result 进行手动结果映射
@Result(column = "dept_id", property = "deptId")column是数据库的名字,property是对象的名字**开启驼峰命名(推荐)**:如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
驼峰命名规则: abc_xyz => abcXyz
- 表中字段名:abc_xyz
- 类中属性名:abcXyz
1
2# 在application.properties中添加:
mybatis.configuration.map-underscore-to-camel-case=true如果要用到类似于’%xxx%’的情况下:
使用MySQL提供的字符串拼接函数:concat(‘%’ , ‘关键字’ , ‘%’)
1
2
3
4
5
6
7
8
9
10
11
12
public interface EmpMapper {
public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);
}如果要使用LocalDate类型,可以直接使用之。比如LocalDate sp, #{sp}
XML映射文件
XML配置文件规范
使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
XML映射文件的namespace属性为Mapper接口全限定名一致
XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。
在resources包中创建包的时候要用/进行分割,不能用.进行分割!
XML配置文件的实现
编写XML映射文件
xml映射文件中的dtd约束,直接从mybatis官网复制即可
1
2
3
4
5
6
7
<mapper namespace="">
</mapper>配置:XML映射文件的namespace属性为Mapper接口全限定名。
配置:XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<mapper namespace="com.itheima.mapper.EmpMapper">
<!--查询操作-->
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
where name like concat('%',#{name},'%')
and gender = #{gender}
and entrydate between #{begin} and #{end}
order by update_time desc
</select>
</mapper>使用:
1
public List<Emp> list(String name, Short gender, LocalDate begin , LocalDate end);
MyBatisX的使用
可以通过MybatisX快速定位
动态SQL
SQL语句会随着用户的输入或外部条件的变化而变化,我们称为:动态SQL。
在Mybatis中提供了很多实现动态SQL的标签,我们学习Mybatis中的动态SQL就是掌握这些动态SQL标签。基于XML的查询
动态SQL-if
<if>:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。1
2
3<if test="条件表达式">
要拼接的sql语句
</if>动态SQL-foreach
<foreach>
1
2
3<foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符"
open="遍历开始前拼接的片段" close="遍历结束后拼接的片段">
</foreach>动态SQL-sql&include
我们可以对重复的代码片段进行抽取,将其通过
<sql>标签封装到一个SQL片段,然后再通过<include>标签进行引用。<sql>:定义可重用的SQL片段。字段名叫做id<include>:通过属性refid,指定包含的SQL片段
案例
文件存储
存储在本地上
前端:需要定义一个表单:
设置form表单中enctype属性值为multipart/form-data,会是什么情况?
1
2
3
4
5
6<form action="/upload" method="post" enctype="multipart/form-data">
姓名: <input type="text" name="username"><br>
年龄: <input type="text" name="age"><br>
头像: <input type="file" name="image"><br>
<input type="submit" value="提交">
</form>表单的enctype得是multipart/form-data
知道了前端程序中需要设置上传文件页面三要素,那我们的后端程序又是如何实现的呢?
首先在服务端定义这么一个controller,用来进行文件上传,然后在controller当中定义一个方法来处理 请求
在定义的方法中接收提交过来的数据 (方法中的形参名和请求参数的名字保持一致)
- 用户名:String name
- 年龄: Integer age
- 文件: MultipartFile image
代码实现:
- 在服务器本地磁盘上创建images目录,用来存储上传的文件(例:E盘创建images目录)
- 使用MultipartFile类提供的API方法,把临时文件转存到本地磁盘目录下
MultipartFile 常见方法:
- String getOriginalFilename(); //获取原始文件名
- void transferTo(File dest); //将接收的文件转存到磁盘文件中
- long getSize(); //获取文件的大小,单位:字节
- byte[] getBytes(); //获取文件内容的字节数组
- InputStream getInputStream(); //获取接收到的文件内容的输入流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class UploadController {
public Result upload(String username, Integer age, MultipartFile image) throws IOException {
log.info("文件上传:{},{},{}",username,age,image);
//获取原始文件名
String originalFilename = image.getOriginalFilename();
//将文件存储在服务器的磁盘目录
image.transferTo(new File("E:/images/"+originalFilename));
return Result.success();
}
}但是这样子有一个问题,就是用户提交了两个一样的文件,就会产生冲突,这个时候就可以使用uuid生成一个互异的文件名。
保证每次上传文件时文件名都唯一的(使用UUID获取随机文件名)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class UploadController {
public Result upload(String username, Integer age, MultipartFile image) throws IOException {
log.info("文件上传:{},{},{}",username,age,image);
//获取原始文件名
String originalFilename = image.getOriginalFilename();
//构建新的文件名
String extname = originalFilename.substring(originalFilename.lastIndexOf("."));//文件扩展名
String newFileName = UUID.randomUUID().toString()+extname;//随机名+文件扩展名
//将文件存储在服务器的磁盘目录
image.transferTo(new File("E:/images/"+newFileName));
return Result.success();
}
}那么如果需要上传大文件,可以在application.properties进行如下配置:
1
2
3
4
5#配置单个文件最大上传大小
spring.servlet.multipart.max-file-size=10MB
#配置单个请求最大上传大小(一次请求可以上传多个文件)
spring.servlet.multipart.max-request-size=100MB存储在阿里云上
准备SDK
云服务指的就是通过互联网对外提供的各种各样的服务,比如像:语音服务、短信服务、邮件服务、视频直播服务、文字识别服务、对象存储服务等等。
当我们在项目开发时需要用到某个或某些服务,就不需要自己来开发了,可以直接使用阿里云提供好的这些现成服务就可以了。比如:在项目开发当中,我们要实现一个短信发送的功能,如果我们项目组自己实现,将会非常繁琐,因为你需要和各个运营商进行对接。而此时阿里云完成了和三大运营商对接,并对外提供了一个短信服务。我们项目组只需要调用阿里云提供的短信服务,就可以很方便的来发送短信了。这样就降低了我们项目的开发难度,同时也提高了项目的开发效率。(大白话:别人帮我们实现好了功能,我们只要调用即可)
云服务提供商给我们提供的软件服务通常是需要收取一部分费用的。
阿里云对象存储OSS(Object Storage Service),是一款海量、安全、低成本、高可靠的云存储服务。使用OSS,您可以通过网络随时存储和调用包括文本、图片、音频和视频等在内的各种文件。
在我们使用了阿里云OSS对象存储服务之后,我们的项目当中如果涉及到文件上传这样的业务,在前端进行文件上传并请求到服务端时,在服务器本地磁盘当中就不需要再来存储文件了。我们直接将接收到的文件上传到oss,由 oss帮我们存储和管理,同时阿里云的oss存储服务还保障了我们所存储内容的安全可靠。
通用思路是:
- 开通OSS对象存储服务
- 创建一个Bucket,选择(标准存储+公共读)
- 获取Access Key(密钥)
入门程序
首先再Maven中添加aliyun的相关依赖
参照官方提供的SDK,改造一下,即可实现文件上传功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60import com.aliyun.oss.ClientException;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.OSSException;
import com.aliyun.oss.model.PutObjectRequest;
import com.aliyun.oss.model.PutObjectResult;
import java.io.FileInputStream;
import java.io.InputStream;
public class AliOssTest {
public static void main(String[] args) throws Exception {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "oss-cn-shanghai.aliyuncs.com";
// 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户。
String accessKeyId = "LTAI5t9MZK8iq5T2Av5GLDxX";
String accessKeySecret = "C0IrHzKZGKqU8S7YQcevcotD3Zd5Tc";
// 填写Bucket名称,例如examplebucket。
String bucketName = "web-framework01";
// 填写Object完整路径,完整路径中不能包含Bucket名称,例如exampledir/exampleobject.txt。
String objectName = "1.jpg";
// 填写本地文件的完整路径,例如D:\\localpath\\examplefile.txt。
// 如果未指定本地路径,则默认从示例程序所属项目对应本地路径中上传文件流。
String filePath= "C:\\Users\\Administrator\\Pictures\\1.jpg";
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
try {
InputStream inputStream = new FileInputStream(filePath);
// 创建PutObjectRequest对象。
PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, objectName, inputStream);
// 设置该属性可以返回response。如果不设置,则返回的response为空。
putObjectRequest.setProcess("true");
// 创建PutObject请求。
PutObjectResult result = ossClient.putObject(putObjectRequest);
// 如果上传成功,则返回200。
System.out.println(result.getResponse().getStatusCode());
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
}
}在以上代码中,需要替换的内容为:
- accessKeyId:阿里云账号AccessKey
- accessKeySecret:阿里云账号AccessKey对应的秘钥
- bucketName:Bucket名称
- objectName:对象名称,在Bucket中存储的对象的名称
- filePath:文件路径
参数配置
Value注解
我们可以将参数配置在配置文件中。如下:
1
2
3
4
5#自定义的阿里云OSS配置信息
aliyun.oss.endpoint=https://oss-cn-hangzhou.aliyuncs.com
aliyun.oss.accessKeyId=LTAI4GCH1vX6DKqJWxd6nEuW
aliyun.oss.accessKeySecret=yBshYweHOpqDuhCArrVHwIiBKpyqSL
aliyun.oss.bucketName=web-tlias在将阿里云OSS配置参数交给properties配置文件来管理之后,我们的AliOSSUtils工具类就变为以下形式:
1
2
3
4
5
6
7
8
9
10
public class AliOSSUtils {
/*以下4个参数没有指定值(默认值:null)*/
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
//省略其他代码...
}而此时如果直接调用AliOSSUtils类当中的upload方法进行文件上传时,这4项参数全部为null,原因是因为并没有给它赋值。
此时我们是不是需要将配置文件当中所配置的属性值读取出来,并分别赋值给AliOSSUtils工具类当中的各个属性呢?那应该怎么做呢?
因为application.properties是springboot项目默认的配置文件,所以springboot程序在启动时会默认读取application.properties配置文件,而我们可以使用一个现成的注解:@Value,获取配置文件中的数据。
@Value 注解通常用于外部配置的属性注入,具体用法为: @Value(“${配置文件中的key}”)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class AliOSSUtils {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
//省略其他代码...
}yml
我们一直使用springboot项目创建完毕后自带的application.properties进行属性的配置,那其实呢,在springboot项目当中是支持多种配置方式的,除了支持properties配置文件以外,还支持另外一种类型的配置文件,就是我们接下来要讲解的yml格式的配置文件。
application.properties
1
2server.port=8080
server.address=127.0.0.1application.yml
1
2
3server:
port: 8080
address: 127.0.0.1application.yaml
1
2
3server:
port: 8080
address: 127.0.0.1
yml 格式的配置文件,后缀名有两种:
- yml (推荐)
- yaml
yml配置文件的基本语法:
- 大小写敏感
- 数值前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格)
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#表示注释,从这个字符一直到行尾,都会被解析器忽略
yml文件中常见的数据格式。在这里我们主要介绍最为常见的两类:
- 定义对象或Map集合
- 定义数组、list或set集合
对象/Map集合
1
2
3
4user:
name: zhangsan
age: 18
password: 123456数组/List/Set集合
1
2
3
4hobby:
- java
- game
- sport熟悉完了yml文件的基本语法后,我们修改下之前案例中使用的配置文件,变更为application.yml配置方式:
- 修改application.properties名字为:
_application.properties(名字随便更换,只要加载不到即可) - 创建新的配置文件:
application.yml
ConfigurationProperties注解
Spring提供的简化方式套路:
需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致
比如:配置文件当中叫endpoints,实体类当中的属性也得叫endpoints,另外实体类当中的属性还需要提供 getter / setter方法
需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象
在实体类上添加
@ConfigurationProperties注解,并通过perfect属性来指定配置参数项的前缀
实体类:AliOSSProperties
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
/*阿里云OSS相关配置*/
public class AliOSSProperties {
//区域
private String endpoint;
//身份ID
private String accessKeyId ;
//身份密钥
private String accessKeySecret ;
//存储空间
private String bucketName;
}AliOSSUtils工具类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.io.InputStream;
import java.util.UUID;
//当前类对象由Spring创建和管理
public class AliOSSUtils {
//注入配置参数实体类对象
private AliOSSProperties aliOSSProperties;
/**
* 实现上传图片到OSS
*/
public String upload(MultipartFile multipartFile) throws IOException {
// 获取上传的文件的输入流
InputStream inputStream = multipartFile.getInputStream();
// 避免文件覆盖
String originalFilename = multipartFile.getOriginalFilename();
String fileName = UUID.randomUUID().toString() + originalFilename.substring(originalFilename.lastIndexOf("."));
//上传文件到 OSS,在这里就可以获取到原始的数据了!
OSS ossClient = new OSSClientBuilder().build(aliOSSProperties.getEndpoint(),
aliOSSProperties.getAccessKeyId(), aliOSSProperties.getAccessKeySecret());
ossClient.putObject(aliOSSProperties.getBucketName(), fileName, inputStream);
//文件访问路径
String url =aliOSSProperties.getEndpoint().split("//")[0] + "//" + aliOSSProperties.getBucketName() + "." + aliOSSProperties.getEndpoint().split("//")[1] + "/" + fileName;
// 关闭ossClient
ossClient.shutdown();
return url;// 把上传到oss的路径返回
}
}在我们添加上注解后,会发现idea窗口上面出现一个红色警告:这个警告提示是告知我们还需要引入一个依赖:
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>登录校验
会话
在web开发当中,会话指的就是浏览器与服务器之间的一次连接,我们就称为一次会话。
在用户打开浏览器第一次访问服务器的时候,这个会话就建立了,直到有任何一方断开连接,此时会话就结束了。在一次会话当中,是可以包含多次请求和响应的。
比如:打开了浏览器来访问web服务器上的资源(浏览器不能关闭、服务器不能断开)
- 第1次:访问的是登录的接口,完成登录操作
- 第2次:访问的是部门管理接口,查询所有部门数据
- 第3次:访问的是员工管理接口,查询员工数据
只要浏览器和服务器都没有关闭,以上3次请求都属于一次会话当中完成的。
需要注意的是:会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话。同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。
知道了会话的概念了,接下来我们再来了解下会话跟踪。
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一浏览器,以便在同一次会话的多次请求间共享数据。
服务器会接收很多的请求,但是服务器是需要识别出这些请求是不是同一个浏览器发出来的。
我们使用会话跟踪技术就是要完成在同一个会话中,多个请求之间进行共享数据。
为什么要共享数据呢?
由于HTTP是无状态协议,在后面请求中怎么拿到前一次请求生成的数据呢?此时就需要在一次会话的多次请求之间进行数据共享
会话跟踪技术有两种:
- Cookie(客户端会话跟踪技术)
- 数据存储在客户端浏览器当中
- Session(服务端会话跟踪技术)
- 数据存储在储在服务端
- 令牌技术
Cookie
cookie 是客户端会话跟踪技术,它是存储在客户端浏览器的,我们使用 cookie 来跟踪会话,我们就可以在浏览器第一次发起请求来请求服务器的时候,我们在服务器端来设置一个cookie。
比如第一次请求了登录接口,登录接口执行完成之后,我们就可以设置一个cookie,在 cookie 当中我们就可以来存储用户相关的一些数据信息。比如我可以在 cookie 当中来存储当前登录用户的用户名,用户的ID。
服务器端在给客户端在响应数据的时候,会自动的将 cookie 响应给浏览器,浏览器接收到响应回来的 cookie 之后,会自动的将 cookie 的值存储在浏览器本地。接下来在后续的每一次请求当中,都会将浏览器本地所存储的 cookie 自动地携带到服务端。
接下来在服务端我们就可以获取到 cookie 的值。我们可以去判断一下这个 cookie 的值是否存在,如果不存在这个cookie,就说明客户端之前是没有访问登录接口的;如果存在 cookie 的值,就说明客户端之前已经登录完成了。这样我们就可以基于 cookie 在同一次会话的不同请求之间来共享数据。
我刚才在介绍流程的时候,用了 3 个自动:
服务器会 自动 的将 cookie 响应给浏览器。
浏览器接收到响应回来的数据之后,会 自动 的将 cookie 存储在浏览器本地。
在后续的请求当中,浏览器会 自动 的将 cookie 携带到服务器端。
为什么这一切都是自动化进行的?
是因为 cookie 它是 HTTP 协议当中所支持的技术,而各大浏览器厂商都支持了这一标准。在 HTTP 协议官方给我们提供了一个响应头和请求头:
响应头 Set-Cookie :设置Cookie数据的
请求头 Cookie:携带Cookie数据的
代码测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class SessionController {
//设置Cookie
//可以直接获取到响应对象,然后对响应对象进行处理
public Result cookie1(HttpServletResponse response){
response.addCookie(new Cookie("login_username","itheima")); //设置Cookie/响应Cookie
return Result.success();
}
//获取Cookie
public Result cookie2(HttpServletRequest request){
Cookie[] cookies = request.getCookies();
for (Cookie cookie : cookies) {
if(cookie.getName().equals("login_username")){
System.out.println("login_username: "+cookie.getValue()); //输出name为login_username的cookie
}
}
return Result.success();
}
}跨域介绍:(Cookie不能跨域)
- 现在的项目,大部分都是前后端分离的,前后端最终也会分开部署,前端部署在服务器 192.168.150.200 上,端口 80,后端部署在 192.168.150.100上,端口 8080
- 我们打开浏览器直接访问前端工程,访问url:http://192.168.150.200/login.html
- 然后在该页面发起请求到服务端,而服务端所在地址不再是localhost,而是服务器的IP地址192.168.150.100,假设访问接口地址为:http://192.168.150.100:8080/login
- 那此时就存在跨域操作了,因为我们是在 http://192.168.150.200/login.html 这个页面上访问了http://192.168.150.100:8080/login 接口
- 此时如果服务器设置了一个Cookie,这个Cookie是不能使用的,因为Cookie无法跨域
区分跨域的维度:
- 协议
- IP/协议
- 端口
只要上述的三个维度有任何一个维度不同,那就是跨域操作。
Session
所以它是存储在服务器端的。而 Session 的底层其实就是基于我们刚才所介绍的 Cookie 来实现的。
获取Session
如果我们现在要基于 Session 来进行会话跟踪,浏览器在第一次请求服务器的时候,我们就可以直接在服务器当中来获取到会话对象Session。如果是第一次请求Session ,会话对象是不存在的,这个时候服务器会自动的创建一个会话对象Session 。而每一个会话对象Session ,它都有一个ID(示意图中Session后面括号中的1,就表示ID),我们称之为 Session 的ID。
响应Cookie (JSESSIONID)
接下来,服务器端在给浏览器响应数据的时候,它会将 Session 的 ID 通过 Cookie 响应给浏览器。其实在响应头当中增加了一个 Set-Cookie 响应头。这个 Set-Cookie 响应头对应的值是不是cookie? cookie 的名字是固定的 JSESSIONID 代表的服务器端会话对象 Session 的 ID。浏览器会自动识别这个响应头,然后自动将Cookie存储在浏览器本地。
查找Session
接下来,在后续的每一次请求当中,都会将 Cookie 的数据获取出来,并且携带到服务端。接下来服务器拿到JSESSIONID这个 Cookie 的值,也就是 Session 的ID。拿到 ID 之后,就会从众多的 Session 当中来找到当前请求对应的会话对象Session。
代码测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class SessionController {
// 获取session,如果存在直接使用,如果不存在会创建一个然后再做操作。
// 返回的时候会返回Session的ID
public Result session1(HttpSession session){
log.info("HttpSession-s1: {}", session.hashCode());
session.setAttribute("loginUser", "tom"); //往session中存储数据
return Result.success();
}
public Result session2(HttpServletRequest request){
HttpSession session = request.getSession();
log.info("HttpSession-s2: {}", session.hashCode());
Object loginUser = session.getAttribute("loginUser"); //从session中获取数据
log.info("loginUser: {}", loginUser);
return Result.success(loginUser);
}
}令牌
这里我们所提到的令牌,其实它就是一个用户身份的标识,看似很高大上,很神秘,其实本质就是一个字符串。
如果通过令牌技术来跟踪会话,我们就可以在浏览器发起请求。在请求登录接口的时候,如果登录成功,我就可以生成一个令牌,令牌就是用户的合法身份凭证。接下来我在响应数据的时候,我就可以直接将令牌响应给前端。
接下来我们在前端程序当中接收到令牌之后,就需要将这个令牌存储起来。这个存储可以存储在 cookie 当中,也可以存储在其他的存储空间(比如:localStorage)当中。
接下来,在后续的每一次请求当中,都需要将令牌携带到服务端。携带到服务端之后,接下来我们就需要来校验令牌的有效性。如果令牌是有效的,就说明用户已经执行了登录操作,如果令牌是无效的,就说明用户之前并未执行登录操作。
此时,如果是在同一次会话的多次请求之间,我们想共享数据,我们就可以将共享的数据存储在令牌当中就可以了。
JWT令牌
前面我们介绍了基于令牌技术来实现会话追踪。这里所提到的令牌就是用户身份的标识,其本质就是一个字符串。令牌的形式有很多,我们使用的是功能强大的 JWT令牌。
JWT全称:JSON Web Token (官网:https://jwt.io/)
定义了一种简洁的、自包含的格式,用于在通信双方以json数据格式安全的传输信息。由于数字签名的存在,这些信息是可靠的。
简洁:是指jwt就是一个简单的字符串。可以在请求参数或者是请求头当中直接传递。
自包含:指的是jwt令牌,看似是一个随机的字符串,但是我们是可以根据自身的需求在jwt令牌中存储自定义的数据内容。如:可以直接在jwt令牌中存储用户的相关信息。
简单来讲,jwt就是将原始的json数据格式进行了安全的封装,这样就可以直接基于jwt在通信双方安全的进行信息传输了。
JWT的组成: (JWT令牌由三个部分组成,三个部分之间使用英文的点来分割)
第一部分:Header(头), 记录令牌类型、签名算法等。 例如:{“alg”:”HS256”,”type”:”JWT”}
第二部分:Payload(有效载荷),携带一些自定义信息、默认信息等。 例如:{“id”:”1”,”username”:”Tom”}
第三部分:Signature(签名),防止Token被篡改、确保安全性。将header、payload,并加入指定秘钥,通过指定签名算法计算而来。
签名的目的就是为了防jwt令牌被篡改,而正是因为jwt令牌最后一个部分数字签名的存在,所以整个jwt 令牌是非常安全可靠的。一旦jwt令牌当中任何一个部分、任何一个字符被篡改了,整个令牌在校验的时候都会失败,所以它是非常安全可靠的。
JWT是如何将原始的JSON格式数据,转变为字符串的呢?
其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
Base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味着也能解码。所使用的64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
需要注意的是Base64是编码方式,而不是加密方式。
JWT令牌最典型的应用场景就是登录认证:
- 在浏览器发起请求来执行登录操作,此时会访问登录的接口,如果登录成功之后,我们需要生成一个jwt令牌,将生成的 jwt令牌返回给前端。
- 前端拿到jwt令牌之后,会将jwt令牌存储起来。在后续的每一次请求中都会将jwt令牌携带到服务端。
- 服务端统一拦截请求之后,先来判断一下这次请求有没有把令牌带过来,如果没有带过来,直接拒绝访问,如果带过来了,还要校验一下令牌是否是有效。如果有效,就直接放行进行请求的处理。
在JWT登录认证的场景中我们发现,整个流程当中涉及到两步操作:
- 在登录成功之后,要生成令牌。
- 每一次请求当中,要接收令牌并对令牌进行校验。
使用JWT
首先我们先来实现JWT令牌的生成。要想使用JWT令牌,需要先引入JWT的依赖:
1
2
3
4
5
6<!-- JWT依赖-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>在引入完JWT来赖后,就可以调用工具包中提供的API来完成JWT令牌的生成和校验
工具类:Jwts
生成JWT代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public void genJwt(){
Map<String,Object> claims = new HashMap<>();
claims.put("id",1);
claims.put("username","Tom");
String jwt = Jwts.builder()
.setClaims(claims) //自定义内容(载荷)
.signWith(SignatureAlgorithm.HS256, "itheima") //签名算法
.setExpiration(new Date(System.currentTimeMillis() + 24*3600*1000)) //有效期
.compact();
System.out.println(jwt);
}运行测试方法:
1
eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MSwiZXhwIjoxNjcyNzI5NzMwfQ.fHi0Ub8npbyt71UqLXDdLyipptLgxBUg_mSuGJtXtBk
输出的结果就是生成的JWT令牌,,通过英文的点分割对三个部分进行分割,我们可以将生成的令牌复制一下,然后打开JWT的官网,将生成的令牌直接放在Encoded位置,此时就会自动的将令牌解析出来。
实现了JWT令牌的生成,下面我们接着使用Java代码来校验JWT令牌(解析生成的令牌):
1
2
3
4
5
6
7
8
9
public void parseJwt(){
Claims claims = Jwts.parser()
.setSigningKey("itheima")//指定签名密钥(必须保证和生成令牌时使用相同的签名密钥)
.parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MSwiZXhwIjoxNjcyNzI5NzMwfQ.fHi0Ub8npbyt71UqLXDdLyipptLgxBUg_mSuGJtXtBk")
.getBody();
System.out.println(claims);
}运行测试方法:
1
{id=1, exp=1672729730}
令牌解析后,我们可以看到id和过期时间,如果在解析的过程当中没有报错,就说明解析成功了。
下面我们做一个测试:把令牌header中的数字9变为8,运行测试方法后发现报错:
修改生成令牌的时指定的过期时间,修改为1分钟
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public void genJwt(){
Map<String,Object> claims = new HashMap<>();
claims.put(“id”,1);
claims.put(“username”,“Tom”);
String jwt = Jwts.builder()
.setClaims(claims) //自定义内容(载荷)
.signWith(SignatureAlgorithm.HS256, “itheima”) //签名算法
.setExpiration(new Date(System.currentTimeMillis() + 60*1000)) //有效期60秒
.compact();
System.out.println(jwt);
//输出结果:eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MSwiZXhwIjoxNjczMDA5NzU0fQ.RcVIR65AkGiax-ID6FjW60eLFH3tPTKdoK7UtE4A1ro
}
public void parseJwt(){
Claims claims = Jwts.parser()
.setSigningKey("itheima")//指定签名密钥
.parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MSwiZXhwIjoxNjczMDA5NzU0fQ.RcVIR65AkGiax-ID6FjW60eLFH3tPTKdoK7UtE4A1ro")
.getBody();
System.out.println(claims);
}等待1分钟之后运行测试方法发现也报错了,说明:JWT令牌过期后,令牌就失效了,解析的为非法令牌。
通过以上测试,我们在使用JWT令牌时需要注意:
JWT校验时使用的签名秘钥,必须和生成JWT令牌时使用的秘钥是配套的。
如果JWT令牌解析校验时报错,则说明 JWT令牌被篡改 或 失效了,令牌非法。
Filter
什么是Filter?
- Filter表示过滤器,是 JavaWeb三大组件(Servlet、Filter、Listener)之一。
- 过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
- 过滤器一般完成一些通用的操作,比如:登录校验、统一编码处理、敏感字符处理等。
下面我们通过Filter快速入门程序掌握过滤器的基本使用操作:
- 第1步,定义过滤器 :1.定义一个类,实现 Filter 接口,并重写其所有方法。
- 第2步,配置过滤器:Filter类上加 @WebFilter 注解,配置拦截资源的路径。引导类上加 @ServletComponentScan 开启Servlet组件支持。
定义过滤器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//定义一个类,实现一个标准的Filter过滤器的接口
public class DemoFilter implements Filter {
//初始化方法, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init 初始化方法执行了");
}
//拦截到请求之后调用, 调用多次
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("Demo 拦截到了请求...放行前逻辑");
//放行
chain.doFilter(request,response);
}
//销毁方法, 只调用一次
public void destroy() {
System.out.println("destroy 销毁方法执行了");
}
}init方法:过滤器的初始化方法。在web服务器启动的时候会自动的创建Filter过滤器对象,在创建过滤器对象的时候会自动调用init初始化方法,这个方法只会被调用一次。
doFilter方法:这个方法是在每一次拦截到请求之后都会被调用,所以这个方法是会被调用多次的,每拦截到一次请求就会调用一次doFilter()方法。
destroy方法: 是销毁的方法。当我们关闭服务器的时候,它会自动的调用销毁方法destroy,而这个销毁方法也只会被调用一次。
在定义完Filter之后,Filter其实并不会生效,还需要完成Filter的配置,Filter的配置非常简单,只需要在Filter类上添加一个注解:@WebFilter,并指定属性urlPatterns,通过这个属性指定过滤器要拦截哪些请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//配置过滤器要拦截的请求路径( /* 表示拦截浏览器的所有请求 )
public class DemoFilter implements Filter {
//初始化方法, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init 初始化方法执行了");
}
//拦截到请求之后调用, 调用多次
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("Demo 拦截到了请求...放行前逻辑");
//放行
chain.doFilter(request,response);
}
//销毁方法, 只调用一次
public void destroy() {
System.out.println("destroy 销毁方法执行了");
}
}当我们在Filter类上面加了@WebFilter注解之后,接下来我们还需要在启动类上面加上一个注解@ServletComponentScan,通过这个@ServletComponentScan注解来开启SpringBoot项目对于Servlet组件的支持。
1
2
3
4
5
6
7
8
9
public class TliasWebManagementApplication {
public static void main(String[] args) {
SpringApplication.run(TliasWebManagementApplication.class, args);
}
}重新启动服务,打开浏览器,执行部门管理的请求,可以看到控制台输出了过滤器中的内容:

注意事项:
在过滤器Filter中,如果不执行放行操作,将无法访问后面的资源。 放行操作:chain.doFilter(request, response);
现在我们已完成了Filter过滤器的基本使用,下面我们将学习Filter过滤器在使用过程中的一些细节。
Filter过滤器的快速入门程序我们已经完成了,接下来我们就要详细的介绍一下过滤器Filter在使用中的一些细节。主要介绍以下3个方面的细节:
- 过滤器的执行流程
- 过滤器的拦截路径配置
- 过滤器链
执行流程
过滤器当中我们拦截到了请求之后,如果希望继续访问后面的web资源,就要执行放行操作,放行就是调用 FilterChain对象当中的doFilter()方法,在调用doFilter()这个方法之前所编写的代码属于放行之前的逻辑。
在放行后访问完 web 资源之后还会回到过滤器当中,回到过滤器之后如有需求还可以执行放行之后的逻辑,放行之后的逻辑我们写在doFilter()这行代码之后。
执行顺序:放行前逻辑->放行doFilter()->执行后面的后端操作->放行后逻辑。
拦截路径
执行流程我们搞清楚之后,接下来再来介绍一下过滤器的拦截路径,Filter可以根据需求,配置不同的拦截资源路径:
拦截路径 urlPatterns值 含义 拦截具体路径 /login 只有访问 /login 路径时,才会被拦截 目录拦截 /emps/* 访问/emps下的所有资源,都会被拦截 拦截所有 /* 访问所有资源,都会被拦截 过滤器链
什么是过滤器链呢?所谓过滤器链指的是在一个web应用程序当中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链。
比如:在我们web服务器当中,定义了两个过滤器,这两个过滤器就形成了一个过滤器链。
而这个链上的过滤器在执行的时候会一个一个的执行,会先执行第一个Filter,放行之后再来执行第二个Filter,如果执行到了最后一个过滤器放行之后,才会访问对应的web资源。
访问完web资源之后,按照我们刚才所介绍的过滤器的执行流程,还会回到过滤器当中来执行过滤器放行后的逻辑,而在执行放行后的逻辑的时候,顺序是反着的。
执行顺序和过滤器的类名有关系。以注解方式配置的Filter过滤器,它的执行优先级是按时过滤器类名的自动排序确定的,类名排名越靠前,优先级越高。
Interceptor(拦截器)
什么是拦截器?
- 是一种动态拦截方法调用的机制,类似于过滤器。
- 拦截器是Spring框架中提供的,用来动态拦截控制器方法的执行。
拦截器的作用:
- 拦截请求,在指定方法调用前后,根据业务需要执行预先设定的代码。
在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带JWT令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。
下面我们通过快速入门程序,来学习下拦截器的基本使用。拦截器的使用步骤和过滤器类似,也分为两步:
定义拦截器
注册配置拦截器
自定义拦截器:实现HandlerInterceptor接口,并重写其所有方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23//自定义拦截器
public class LoginCheckInterceptor implements HandlerInterceptor {
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle .... ");
return true; //true表示放行
}
//目标资源方法执行后执行
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("postHandle ... ");
}
//视图渲染完毕后执行,最后执行
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("afterCompletion .... ");
}
}注意:
preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行
postHandle方法:目标资源方法执行后执行
afterCompletion方法:视图渲染完毕后执行,最后执行
注册配置拦截器:实现WebMvcConfigurer接口,并重写addInterceptors方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class WebConfig implements WebMvcConfigurer {
//自定义的拦截器对象
private LoginCheckInterceptor loginCheckInterceptor;
public void addInterceptors(InterceptorRegistry registry) {
//注册自定义拦截器对象
registry.addInterceptor(loginCheckInterceptor).addPathPatterns("/**");//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
}
}拦截路径
首先我们先来看拦截器的拦截路径的配置,在注册配置拦截器的时候,我们要指定拦截器的拦截路径,通过
addPathPatterns("要拦截路径")方法,就可以指定要拦截哪些资源。在入门程序中我们配置的是
/**,表示拦截所有资源,而在配置拦截器时,不仅可以指定要拦截哪些资源,还可以指定不拦截哪些资源,只需要调用excludePathPatterns("不拦截路径")方法,指定哪些资源不需要拦截。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class WebConfig implements WebMvcConfigurer {
//拦截器对象
private LoginCheckInterceptor loginCheckInterceptor;
public void addInterceptors(InterceptorRegistry registry) {
//注册自定义拦截器对象
registry.addInterceptor(loginCheckInterceptor)
.addPathPatterns("/**")//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
.excludePathPatterns("/login");//设置不拦截的请求路径
}
}在拦截器中除了可以设置
/**拦截所有资源外,还有一些常见拦截路径设置:拦截路径 含义 举例 /* 一级路径 能匹配/depts,/emps,/login,不能匹配 /depts/1 /** 任意级路径 能匹配/depts,/depts/1,/depts/1/2 /depts/* /depts下的一级路径 能匹配/depts/1,不能匹配/depts/1/2,/depts /depts/** /depts下的任意级路径 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 执行流程
当我们打开浏览器来访问部署在web服务器当中的web应用时,此时我们所定义的过滤器会拦截到这次请求。拦截到这次请求之后,它会先执行放行前的逻辑,然后再执行放行操作。而由于我们当前是基于springboot开发的,所以放行之后是进入到了spring的环境当中,也就是要来访问我们所定义的controller当中的接口方法。
Tomcat并不识别所编写的Controller程序,但是它识别Servlet程序,所以在Spring的Web环境中提供了一个非常核心的Servlet:DispatcherServlet(前端控制器),所有请求都会先进行到DispatcherServlet,再将请求转给Controller。
当我们定义了拦截器后,会在执行Controller的方法之前,请求被拦截器拦截住。执行
preHandle()方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回true,就表示放行本次操作,才会继续访问controller中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。在controller当中的方法执行完毕之后,再回过来执行
postHandle()这个方法以及afterCompletion()方法,然后再返回给DispatcherServlet,最终再来执行过滤器当中放行后的这一部分逻辑的逻辑。执行完毕之后,最终给浏览器响应数据。
综合起来,在Filter的doFilter执行的时候,拦截器的preHandle->Springboot核心业务->postHandle。
它们之间的区别主要是两点:
- 接口规范不同:过滤器需要实现Filter接口,而拦截器需要实现HandlerInterceptor接口。
- 拦截范围不同:过滤器Filter会拦截所有的资源,而Interceptor只会拦截Spring环境中的资源。
全局异常处理器
我们该怎么样定义全局异常处理器?
- 定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解@RestControllerAdvice,加上这个注解就代表我们定义了一个全局异常处理器。
- 在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解@ExceptionHandler。通过@ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。
1
2
3
4
5
6
7
8
9
10
11
12
public class GlobalExceptionHandler {
//处理异常
//指定能够处理的异常类型
public Result ex(Exception e){
e.printStackTrace();//打印堆栈中的异常信息
//捕获到异常之后,响应一个标准的Result
return Result.error("对不起,操作失败,请联系管理员");
}
}@RestControllerAdvice = @ControllerAdvice + @ResponseBody
处理异常的方法返回值会转换为json后再响应给前端
事务管理
事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体,一起向数据库提交或者是撤销操作请求。所以这组操作要么同时成功,要么同时失败。
怎么样来控制这组操作,让这组操作同时成功或同时失败呢?此时就要涉及到事务的具体操作了。
事务的操作主要有三步:
- 开启事务(一组操作开始前,开启事务):start transaction / begin ;
- 提交事务(这组操作全部成功后,提交事务):commit ;
- 回滚事务(中间任何一个操作出现异常,回滚事务):rollback ;
而要想保证操作前后,数据的一致性,就需要涉及到的两个业务操作,要么全部成功,要么全部失败 。 那我们如何,让这两个操作要么全部成功,要么全部失败呢 ?
那就可以通过事务来实现,因为一个事务中的多个业务操作,要么全部成功,要么全部失败。
@Transactional注解
@Transactional作用:就是在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。
@Transactional注解:我们一般会在业务层当中来控制事务,因为在业务层当中,一个业务功能可能会包含多个数据访问的操作。在业务层来控制事务,我们就可以将多个数据访问操作控制在一个事务范围内。
@Transactional注解书写位置:
- 方法
- 当前方法交给spring进行事务管理
- 类
- 当前类中所有的方法都交由spring进行事务管理
- 接口
- 接口下所有的实现类当中所有的方法都交给spring 进行事务管理
接下来,我们就可以在业务方法delete上加上 @Transactional 来控制事务 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class DeptServiceImpl implements DeptService {
private DeptMapper deptMapper;
private EmpMapper empMapper;
//当前方法添加了事务管理
public void delete(Integer id){
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
int i = 1/0;
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}
}RollbackFor
我们在之前编写的业务方法上添加了@Transactional注解,来实现事务管理。
1
2
3
4
5
6
7
8
9
10
11
public void delete(Integer id){
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
int i = 1/0;
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}以上业务功能delete()方法在运行时,会引发除0的算数运算异常(运行时异常),出现异常之后,由于我们在方法上加了@Transactional注解进行事务管理,所以发生异常会执行rollback回滚操作,从而保证事务操作前后数据是一致的。
下面我们在做一个测试,我们修改业务功能代码,在模拟异常的位置上直接抛出Exception异常(编译时异常)
1
2
3
4
5
6
7
8
9
10
11
12
13
public void delete(Integer id) throws Exception {
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
if(true){
throw new Exception("出现异常了~~~");
}
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}说明:在service中向上抛出一个Exception编译时异常之后,由于是controller调用service,所以在controller中要有异常处理代码,此时我们选择在controller中继续把异常向上抛。
1
2
3
4
5
6
7
8
9
public Result delete( Integer id) throws Exception {
//日志记录
log.info("根据id删除部门");
//调用service层功能
deptService.delete(id);
//响应
return Result.success();
}重新启动服务后测试:
抛出异常之后事务会不会回滚
通过以上测试可以得出一个结论:默认情况下,只有出现**RuntimeException(运行时异常)**才会回滚事务。
假如我们想让所有的异常都回滚,需要来配置@Transactional注解当中的rollbackFor属性,通过rollbackFor这个属性可以指定出现何种异常类型回滚事务。
像这样:
@Transactional(rollbackFor=Exception.class)Propagation
我们接着继续学习@Transactional注解当中的第二个属性propagation,这个属性是用来配置事务的传播行为的。
什么是事务的传播行为呢?
- 就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。
例如:两个事务方法,一个A方法,一个B方法。在这两个方法上都添加了@Transactional注解,就代表这两个方法都具有事务,而在A方法当中又去调用了B方法。
所谓事务的传播行为,指的就是在A方法运行的时候,首先会开启一个事务,在A方法当中又调用了B方法, B方法自身也具有事务,那么B方法在运行的时候,到底是加入到A方法的事务当中来,还是B方法在运行的时候新建一个事务?这个就涉及到了事务的传播行为。
我们要想控制事务的传播行为,在@Transactional注解的后面指定一个属性propagation,通过 propagation 属性来指定传播行为。接下来我们就来介绍一下常见的事务传播行为。
属性值 含义 REQUIRED 【默认值】需要事务,有则加入,无则创建新事务 REQUIRES_NEW 需要新事务,无论有无,总是创建新事务 SUPPORTS 支持事务,有则加入,无则在无事务状态中运行 NOT_SUPPORTED 不支持事务,在无事务状态下运行,如果当前存在已有事务,则挂起当前事务 MANDATORY 必须有事务,否则抛异常 NEVER 必须没事务,否则抛异常 … 对于这些事务传播行为,我们只需要关注以下两个就可以了:
- REQUIRED(默认值)
- REQUIRES_NEW
A事务开启了B事务,A发生了错误,如果是B是REQUIRED,AB都不会提交。如果B是REQUIRES_NEW,那么B提交A不提交,A会回滚。
AOP
什么是AOP?
- AOP英文全称:Aspect Oriented Programming(面向切面编程、面向方面编程),其实说白了,面向切面编程就是面向特定方法编程。
比如:我们只想通过 部门管理的 list 方法的执行耗时,那就只有这一个方法是原始业务方法。 而如果,我们是先想统计所有部门管理的业务方法执行耗时,那此时,所有的部门管理的业务方法都是 原始业务方法。 那面向这样的指定的一个或多个方法进行编程,我们就称之为 面向切面编程。本质上就是”动态代理“。
AOP的优势:
- 减少重复代码
- 提高开发效率
- 维护方便
快速入门
在了解了什么是AOP后,我们下面通过一个快速入门程序,体验下AOP的开发,并掌握Spring中AOP的开发步骤。
需求:统计各个业务层方法执行耗时。
实现步骤:
- 导入依赖:在pom.xml中导入AOP的依赖
- 编写AOP程序:针对于特定方法根据业务需要进行编程
为演示方便,可以自建新项目或导入提供的
springboot-aop-quickstart项目工程pom.xml
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>AOP程序:TimeAspect
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
//当前类为切面类
public class TimeAspect {
// 针对哪些方法来进行AOP编程
public Object recordTime(ProceedingJoinPoint pjp) throws Throwable {
//记录方法执行开始时间
long begin = System.currentTimeMillis();
//执行原始方法
Object result = pjp.proceed();
//记录方法执行结束时间
long end = System.currentTimeMillis();
//计算方法执行耗时
log.info(pjp.getSignature()+"执行耗时: {}毫秒",end-begin);
return result;
}
}基础概念
1. 连接点:JoinPoint,可以被AOP控制的方法(暗含方法执行时的相关信息)
连接点指的是可以被aop控制的方法。例如:入门程序当中所有的业务方法都是可以被aop控制的方法。
2. 通知:Advice,指哪些重复的逻辑,也就是共性功能(最终体现为一个方法)
在入门程序中是需要统计各个业务方法的执行耗时的,此时我们就需要在这些业务方法运行开始之前,先记录这个方法运行的开始时间,在每一个业务方法运行结束的时候,再来记录这个方法运行的结束时间。
但是在AOP面向切面编程当中,我们只需要将这部分重复的代码逻辑抽取出来单独定义。抽取出来的这一部分重复的逻辑,也就是共性的功能。
3. 切入点:PointCut,匹配连接点的条件,通知仅会在切入点方法执行时被应用
在通知当中,我们所定义的共性功能到底要应用在哪些方法上?此时就涉及到了切入点pointcut概念。切入点指的是匹配连接点的条件。通知仅会在切入点方法运行时才会被应用。
在aop的开发当中,我们通常会通过一个切入点表达式来描述切入点(后面会有详解)。
连接点是可以被AOP增强的方法,切入点是最后的确被AOP增强的方法(我要用到的办法)。
4. 切面:Aspect,描述通知与切入点的对应关系(通知+切入点)
当通知和切入点结合在一起,就形成了一个切面。通过切面就能够描述当前aop程序需要针对于哪个原始方法,在什么时候执行什么样的操作。
5. 目标对象:Target,通知所应用的对象
目标对象指的就是通知所应用的对象,我们就称之为目标对象。
Spring的AOP底层是基于动态代理技术来实现的,也就是说在程序运行的时候,会自动的基于动态代理技术为目标对象生成一个对应的代理对象。在代理对象当中就会对目标对象当中的原始方法进行功能的增强。最后注入的时候注入的其实是代理对象。
通知类型
在入门程序当中,我们已经使用了一种功能最为强大的通知类型:Around环绕通知。
1
2
3
4
5
6
7
8
9
10
11
12
public Object recordTime(ProceedingJoinPoint pjp) throws Throwable {
//记录方法执行开始时间
long begin = System.currentTimeMillis();
//执行原始方法
Object result = pjp.proceed();
//记录方法执行结束时间
long end = System.currentTimeMillis();
//计算方法执行耗时
log.info(pjp.getSignature()+"执行耗时: {}毫秒",end-begin);
return result;
}只要我们在通知方法上加上了@Around注解,就代表当前通知是一个环绕通知。
Spring中AOP的通知类型:
- @Around:环绕通知,此注解标注的通知方法在目标方法前、后都被执行
- @Before:前置通知,此注解标注的通知方法在目标方法前被执行
- @After :后置通知,此注解标注的通知方法在目标方法后被执行,无论是否有异常都会执行
- @AfterReturning : 返回后通知,此注解标注的通知方法在目标方法后被执行,有异常不会执行
- @AfterThrowing : 异常后通知,此注解标注的通知方法发生异常后执行
下面我们通过代码演示,来加深对于不同通知类型的理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
public class MyAspect1 {
//前置通知
public void before(JoinPoint joinPoint){
log.info("before ...");
}
//环绕通知
public Object around(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
log.info("around before ...");
//调用目标对象的原始方法执行
Object result = proceedingJoinPoint.proceed();
//原始方法如果执行时有异常,环绕通知中的后置代码不会在执行了
log.info("around after ...");
return result;
}
//后置通知
public void after(JoinPoint joinPoint){
log.info("after ...");
}
//返回后通知(程序在正常执行的情况下,会执行的后置通知)
public void afterReturning(JoinPoint joinPoint){
log.info("afterReturning ...");
}
//异常通知(程序在出现异常的情况下,执行的后置通知)
public void afterThrowing(JoinPoint joinPoint){
log.info("afterThrowing ...");
}
}每一个注解里面都指定了切入点表达式,而且这些切入点表达式都一模一样。此时我们的代码当中就存在了大量的重复性的切入点表达式,假如此时切入点表达式需要变动,就需要将所有的切入点表达式一个一个的来改动,就变得非常繁琐了。
怎么来解决这个切入点表达式重复的问题? 答案就是:抽取
Spring提供了@PointCut注解,该注解的作用是将公共的切入点表达式抽取出来,需要用到时引用该切入点表达式即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
public class MyAspect1 {
//切入点方法(公共的切入点表达式)
private void pt(){
}
//前置通知(引用切入点)
public void before(JoinPoint joinPoint){
log.info("before ...");
}
//环绕通知
public Object around(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
log.info("around before ...");
//调用目标对象的原始方法执行
Object result = proceedingJoinPoint.proceed();
//原始方法在执行时:发生异常
//后续代码不在执行
log.info("around after ...");
return result;
}
//后置通知
public void after(JoinPoint joinPoint){
log.info("after ...");
}
//返回后通知(程序在正常执行的情况下,会执行的后置通知)
public void afterReturning(JoinPoint joinPoint){
log.info("afterReturning ...");
}
//异常通知(程序在出现异常的情况下,执行的后置通知)
public void afterThrowing(JoinPoint joinPoint){
log.info("afterThrowing ...");
}
}需要注意的是:当切入点方法使用private修饰时,仅能在当前切面类中引用该表达式, 当外部其他切面类中也要引用当前类中的切入点表达式,就需要把private改为public,而在引用的时候,具体的语法为:
全类名.方法名(),具体形式如下:
1
2
3
4
5
6
7
8
9
10
public class MyAspect2 {
//引用MyAspect1切面类中的切入点表达式
public void before(){
log.info("MyAspect2 -> before ...");
}
}通知顺序
当在项目开发当中,我们定义了多个切面类,而多个切面类中多个切入点都匹配到了同一个目标方法。此时当目标方法在运行的时候,这多个切面类当中的这些通知方法都会运行。
此时我们就有一个疑问,这多个通知方法到底哪个先运行,哪个后运行? 下面我们通过程序来验证(这里呢,我们就定义两种类型的通知进行测试,一种是前置通知@Before,一种是后置通知@After)
通过以上程序运行可以看出在不同切面类中,默认按照切面类的类名字母排序:
- 目标方法前的通知方法:字母排名靠前的先执行
- 目标方法后的通知方法:字母排名靠前的后执行
如果我们想控制通知的执行顺序有两种方式:
- 修改切面类的类名(这种方式非常繁琐、而且不便管理)
- 使用Spring提供的@Order注解
使用@Order注解,控制通知的执行顺序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//切面类的执行顺序(前置通知:数字越小先执行; 后置通知:数字越小越后执行)
public class MyAspect2 {
//前置通知
public void before(){
log.info("MyAspect2 -> before ...");
}
//后置通知
public void after(){
log.info("MyAspect2 -> after ...");
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//切面类的执行顺序(前置通知:数字越小先执行; 后置通知:数字越小越后执行)
public class MyAspect3 {
//前置通知
public void before(){
log.info("MyAspect3 -> before ...");
}
//后置通知
public void after(){
log.info("MyAspect3 -> after ...");
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//切面类的执行顺序(前置通知:数字越小先执行; 后置通知:数字越小越后执行)
public class MyAspect4 {
//前置通知
public void before(){
log.info("MyAspect4 -> before ...");
}
//后置通知
public void after(){
log.info("MyAspect4 -> after ...");
}
}切入点表达式
切入点表达式:
描述切入点方法的一种表达式
作用:主要用来决定项目中的哪些方法需要加入通知
常见形式:
execution(……):根据方法的签名来匹配
@annotation(……) :根据注解匹配
execution主要根据方法的返回值、包名、类名、方法名、方法参数等信息来匹配,语法为:
1
execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws 异常?)
其中带
?的表示可以省略的部分访问修饰符:可省略(比如: public、protected)
包名.类名: 可省略
throws 异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常)
示例:
1
可以使用通配符描述切入点
*:单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分..:多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数
切入点表达式的语法规则:
- 方法的访问修饰符可以省略
- 返回值可以使用
*号代替(任意返回值类型) - 包名可以使用
*号代替,代表任意包(一层包使用一个*) - 使用
..配置包名,标识此包以及此包下的所有子包(一个..可以代替好几层,这是和第三点的区别) - 类名可以使用
*号代替,标识任意类 - 方法名可以使用
*号代替,表示任意方法 - 可以使用
*配置参数,一个任意类型的参数 - 可以使用
..配置参数,任意个任意类型的参数
切入点表达式示例
省略方法的修饰符号
1
execution(void com.itheima.service.impl.DeptServiceImpl.delete(java.lang.Integer))
使用
*代替返回值类型1
execution(* com.itheima.service.impl.DeptServiceImpl.delete(java.lang.Integer))
使用
*代替包名(一层包使用一个*)1
execution(* com.itheima.*.*.DeptServiceImpl.delete(java.lang.Integer))
使用
..省略包名1
execution(* com..DeptServiceImpl.delete(java.lang.Integer))
使用
*代替类名1
execution(* com..*.delete(java.lang.Integer))
使用
*代替方法名1
execution(* com..*.*(java.lang.Integer))
使用
*代替参数1
execution(* com.itheima.service.impl.DeptServiceImpl.delete(*))
使用
..省略参数1
execution(* com..*.*(..))
注意事项:
根据业务需要,可以使用 且(&&)、或(||)、非(!) 来组合比较复杂的切入点表达式。
1
execution(* com.itheima.service.DeptService.list(..)) || execution(* com.itheima.service.DeptService.delete(..))
@annotation
我们可以借助于另一种切入点表达式annotation来描述这一类的切入点,从而来简化切入点表达式的书写。
实现步骤:
编写自定义注解
在业务类要做为连接点的方法上添加自定义注解
自定义注解:MyLog
1
2
3
4
public MyLog {
}业务类:DeptServiceImpl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
public class DeptServiceImpl implements DeptService {
private DeptMapper deptMapper;
//自定义注解(表示:当前方法属于目标方法)
public List<Dept> list() {
List<Dept> deptList = deptMapper.list();
//模拟异常
//int num = 10/0;
return deptList;
}
//自定义注解(表示:当前方法属于目标方法)
public void delete(Integer id) {
//1. 删除部门
deptMapper.delete(id);
}
public void save(Dept dept) {
dept.setCreateTime(LocalDateTime.now());
dept.setUpdateTime(LocalDateTime.now());
deptMapper.save(dept);
}
public Dept getById(Integer id) {
return deptMapper.getById(id);
}
public void update(Dept dept) {
dept.setUpdateTime(LocalDateTime.now());
deptMapper.update(dept);
}
}切面类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class MyAspect6 {
//针对list方法、delete方法进行前置通知和后置通知
//前置通知
public void before(){
log.info("MyAspect6 -> before ...");
}
//后置通知
public void after(){
log.info("MyAspect6 -> after ...");
}
}连接点
接点可以简单理解为可以被AOP控制的方法。
我们目标对象当中所有的方法是不是都是可以被AOP控制的方法。而在SpringAOP当中,连接点又特指方法的执行。
我们目标对象当中所有的方法是不是都是可以被AOP控制的方法。而在SpringAOP当中,连接点又特指方法的执行。
在Spring中用JoinPoint抽象了连接点,用它可以获得方法执行时的相关信息,如目标类名、方法名、方法参数等。
对于@Around通知,获取连接点信息只能使用ProceedingJoinPoint类型
对于其他四种通知,获取连接点信息只能使用JoinPoint,它是ProceedingJoinPoint的父类型
Springboot原理
配置优先级
在SpringBoot项目当中,我们要想配置一个属性,可以通过这三种方式当中的任意一种来配置都可以,那么如果项目中同时存在这三种配置文件,且都配置了同一个属性,如:Tomcat端口号,到底哪一份配置文件生效呢?
- application.properties
1
server.port=8081
- application.yml
1
2server:
port: 8082- application.yaml
1
2server:
port: 8082配置文件优先级排名(从高到低):
- properties配置文件
- yml配置文件
- yaml配置文件
在SpringBoot项目当中除了以上3种配置文件外,SpringBoot为了增强程序的扩展性,除了支持配置文件的配置方式以外,还支持另外两种常见的配置方式:
Java系统属性配置 (格式: -Dkey=value)
1
-Dserver.port=9000
命令行参数 (格式:–key=value)
1
--server.port=10010
优先级: 命令行参数 > 系统属性参数 > properties参数 > yml参数 > yaml参数
思考:如果项目已经打包上线了,这个时候我们又如何来设置Java系统属性和命令行参数呢?
1
java -Dserver.port=9000 -jar XXXXX.jar --server.port=10010
下面我们来演示下打包程序运行时指定Java系统属性和命令行参数:
- 执行maven打包指令package,把项目打成jar文件
- 使用命令:java -jar 方式运行jar文件程序
在命令行环境中使用jar包
如果自定义的目录,比如conf的话,这个时候就不能识别了,但可以使用–spring.config.location进行指定路径,执行命令如下:
1
java -jar springboot-out-properties-0.0.1-SNAPSHOT.jar--spring.config.location=conf/application.properties
当然也可以使用绝对路径进行指定:
1
java -jar springboot-out-properties-0.0.1-SNAPSHOT.jar--spring.config.location=/Users/linxiangxian/Downloads/conf/application.properties
Bean管理
在前面的课程当中,我们已经讲过了我们可以通过Spring当中提供的注解@Component以及它的三个衍生注解(@Controller、@Service、@Repository)来声明IOC容器中的bean对象,同时我们也学习了如何为应用程序注入运行时所需要依赖的bean对象,也就是依赖注入DI。
我们今天主要学习IOC容器中Bean的其他使用细节,主要学习以下三方面:
- 如何从IOC容器中手动的获取到bean对象
- bean的作用域配置
- 管理第三方的bean对象
除了@AutoWired的bean对象获取
默认情况下,SpringBoot项目在启动的时候会自动的创建IOC容器(也称为Spring容器),并且在启动的过程当中会自动的将bean对象都创建好,存放在IOC容器当中。应用程序在运行时需要依赖什么bean对象,就直接进行依赖注入就可以了。
而在Spring容器中提供了一些方法,可以主动从IOC容器中获取到bean对象,下面介绍3种常用方式:
根据name获取bean
1
Object getBean(String name)
根据类型获取bean
1
<T> T getBean(Class<T> requiredType)
根据name获取bean(带类型转换)
1
<T> T getBean(String name, Class<T> requiredType)
思考:要从IOC容器当中来获取到bean对象,需要先拿到IOC容器对象,怎么样才能拿到IOC容器呢?
- 想获取到IOC容器,直接将IOC容器对象注入进来就可以了
1
2
private ApplicationContext applicationContext; //IOC容器对象(默认情况下,IOC中的bean对象是单例)
那么能不能将bean对象设置为非单例的(每次获取的bean都是一个新对象)?
可以,在下一个知识点(bean作用域)中讲解。
Bean作用域
在前面我们提到的IOC容器当中,默认bean对象是单例模式(只有一个实例对象)。那么如何设置bean对象为非单例呢?需要设置bean的作用域。
在Spring中支持五种作用域,后三种在web环境才生效:
作用域 说明 singleton 容器内同名称的bean只有一个实例(单例)(默认) prototype 每次使用该bean时会创建新的实例(非单例) request 每个请求范围内会创建新的实例(web环境中,了解) session 每个会话范围内会创建新的实例(web环境中,了解) application 每个应用范围内会创建新的实例(web环境中,了解) 知道了bean的5种作用域了,我们要怎么去设置一个bean的作用域呢?
- 可以借助Spring中的@Scope注解来进行配置作用域
默认singleton的bean,在容器启动时被创建,可以使用@Lazy注解来延迟初始化(延迟到第一次使用时)
第三方Bean
学习完bean的获取、bean的作用域之后,接下来我们再来学习第三方bean的配置。
之前我们所配置的bean,像controller、service,dao三层体系下编写的类,这些类都是我们在项目当中自己定义的类(自定义类)。当我们要声明这些bean,也非常简单,我们只需要在类上加上@Component以及它的这三个衍生注解(@Controller、@Service、@Repository)还有@Mapper,就可以来声明这个bean对象了。
但是在我们项目开发当中,还有一种情况就是这个类它不是我们自己编写的,而是我们引入的第三方依赖当中提供的。在pom.xml文件中,引入dom4j:
1
2
3
4
5
6<!--Dom4j-->
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.3</version>
</dependency>dom4j就是第三方组织提供的。 dom4j中的SAXReader类就是第三方编写的。
当我们需要使用到SAXReader对象时,直接进行依赖注入是不是就可以了呢?
- 按照我们之前的做法,需要在SAXReader类上添加一个注解@Component(将当前类交给IOC容器管理)
结论:第三方提供的类是只读的。无法在第三方类上添加@Component注解或衍生注解。
那么我们应该怎样使用并定义第三方的bean呢?
- 如果要管理的bean对象来自于第三方(不是自定义的),是无法用@Component 及衍生注解声明bean的,就需要用到**@Bean**注解。
解决方案:在配置类中定义@Bean标识的方法
- 如果需要定义第三方Bean时, 通常会单独定义一个配置类
1
2
3
4
5
6
7
8
9
10
11
12
13//配置类 (在配置类当中对第三方bean进行集中的配置管理)
public class CommonConfig {
//声明第三方bean
//将当前方法的返回值对象交给IOC容器管理, 成为IOC容器bean
//通过@Bean注解的name/value属性指定bean名称, 如果未指定, 默认是方法名
public SAXReader reader(DeptService deptService){
System.out.println(deptService);
return new SAXReader();
}
}测试类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class SpringbootWebConfig2ApplicationTests {
// 这样,就可以获得SAXReader的Bean对象了
private SAXReader saxReader;
//第三方bean的管理
public void testThirdBean() throws Exception {
Document document = saxReader.read(this.getClass().getClassLoader().getResource("1.xml"));
Element rootElement = document.getRootElement();
String name = rootElement.element("name").getText();
String age = rootElement.element("age").getText();
System.out.println(name + " : " + age);
}
//省略其他代码...
}注释掉SpringBoot启动类中创建第三方bean对象的代码,重启服务,执行测试方法,查看控制台日志:
1
Tom : 18
在方法上加上一个@Bean注解,Spring 容器在启动的时候,它会自动的调用这个方法,并将方法的返回值声明为Spring容器当中的Bean对象。
注意事项 :
通过@Bean注解的name或value属性可以声明bean的名称,如果不指定,默认bean的名称就是方法名。
如果第三方bean需要依赖其它bean对象,直接在bean定义方法中设置形参即可,容器会根据类型自动装配。
关于Bean大家只需要保持一个原则:
- 如果是在项目当中我们自己定义的类,想将这些类交给IOC容器管理,我们直接使用@Component以及它的衍生注解来声明就可以。
- 如果这个类它不是我们自己定义的,而是引入的第三方依赖当中提供的类,而且我们还想将这个类交给IOC容器管理。此时我们就需要在配置类中定义一个方法,在方法上加上一个@Bean注解,通过这种方式来声明第三方的bean对象。
原理
起步依赖
假如我们没有使用SpringBoot,用的是Spring框架进行web程序的开发,此时我们就需要引入web程序开发所需要的一些依赖。
spring-webmvc依赖:这是Spring框架进行web程序开发所需要的依赖
servlet-api依赖:Servlet基础依赖
jackson-databind依赖:JSON处理工具包
如果要使用AOP,还需要引入aop依赖、aspect依赖
项目中所引入的这些依赖,还需要保证版本匹配,否则就可能会出现版本冲突问题。
为什么我们只需要引入一个web开发的起步依赖,web开发所需要的所有的依赖都有了呢?
- 因为Maven的依赖传递。
在SpringBoot给我们提供的这些起步依赖当中,已提供了当前程序开发所需要的所有的常见依赖(官网地址:https://docs.spring.io/spring-boot/docs/2.7.7/reference/htmlsingle/#using.build-systems.starters)。
比如:springboot-starter-web,这是web开发的起步依赖,在web开发的起步依赖当中,就集成了web开发中常见的依赖:json、web、webmvc、tomcat等。我们只需要引入这一个起步依赖,其他的依赖都会自动的通过Maven的依赖传递进来。
自动配置
SpringBoot的自动配置就是当Spring容器启动后,一些配置类、bean对象就自动存入到了IOC容器中,不需要我们手动去声明,从而简化了开发,省去了繁琐的配置操作。
比如:我们要进行事务管理、要进行AOP程序的开发,此时就不需要我们再去手动的声明这些bean对象了,我们直接使用就可以从而大大的简化程序的开发,省去了繁琐的配置操作。
我们知道了什么是自动配置之后,接下来我们就要来剖析自动配置的原理。解析自动配置的原理就是分析在 SpringBoot项目当中,我们引入对应的依赖之后,是如何将依赖jar包当中所提供的bean以及配置类直接加载到当前项目的SpringIOC容器当中的。
思考:引入进来的第三方依赖当中的bean以及配置类为什么没有生效?
- 原因在我们之前讲解IOC的时候有提到过,在类上添加@Component注解来声明bean对象时,还需要保证@Component注解能被Spring的组件扫描到。
- SpringBoot项目中的@SpringBootApplication注解,具有包扫描的作用,但是它只会扫描启动类所在的当前包以及子包。
那么如何解决以上问题的呢?
- 方案1:@ComponentScan 组件扫描
- 方案2:@Import 导入(使用@Import导入的类会被Spring加载到IOC容器中)
@Import导入
- 导入形式主要有以下几种:
- 导入普通类
- 导入配置类
- 导入ImportSelector接口实现类
1). 使用@Import导入普通类:
1
2
3
4
5
6
7//导入的类会被Spring加载到IOC容器中
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}2). 使用@Import导入配置类:
- 配置类
1
2
3
4
5
6
7
8
9
10
11
12
public class HeaderConfig {
public HeaderParser headerParser(){
return new HeaderParser();
}
public HeaderGenerator headerGenerator(){
return new HeaderGenerator();
}
}- 启动类
1
2
3
4
5
6
7//导入配置类
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}- 测试类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class AutoConfigurationTests {
private ApplicationContext applicationContext;
public void testHeaderParser(){
System.out.println(applicationContext.getBean(HeaderParser.class));
}
public void testHeaderGenerator(){
System.out.println(applicationContext.getBean(HeaderGenerator.class));
}
//省略其他代码...
}3). 使用@Import导入ImportSelector接口实现类:
- ImportSelector接口实现类
1
2
3
4
5
6public class MyImportSelector implements ImportSelector {
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
//返回值字符串数组(数组中封装了全限定名称的类)
return new String[]{"com.example.HeaderConfig"};
}
}- 启动类
1
2
3
4
5
6
7
8
9//导入ImportSelector接口实现类
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}执行测试方法:

我们使用@Import注解通过这三种方式都可以导入第三方依赖中所提供的bean或者是配置类。
思考:如果基于以上方式完成自动配置,当要引入一个第三方依赖时,是不是还要知道第三方依赖中有哪些配置类和哪些Bean对象?
- 答案:是的。 (对程序员来讲,很不友好,而且比较繁琐)
思考:当我们要使用第三方依赖,依赖中到底有哪些bean和配置类,谁最清楚?
- 答案:第三方依赖自身最清楚。
结论:我们不用自己指定要导入哪些bean对象和配置类了,让第三方依赖它自己来指定。
怎么让第三方依赖自己指定bean对象和配置类?
- 比较常见的方案就是第三方依赖给我们提供一个注解,这个注解一般都以@EnableXxxx开头的注解,注解中封装的就是@Import注解
4). 使用第三方依赖提供的 @EnableXxxxx注解
- 第三方依赖中提供的注解
1
2
3
4
5
//指定要导入哪些bean对象或配置类
public EnableHeaderConfig {
}- 在使用时只需在启动类上加上@EnableXxxxx注解即可
1
2
3
4
5
6
7
8//使用第三方依赖提供的Enable开头的注解
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}@Configuration
Spring框架中,Bean是指由Spring容器管理的对象。Spring容器负责创建、配置和管理这些对象的生命周期。Bean通常是应用程序中的组件,如服务、存储库、控制器等。
配置类是使用Java代码来配置Spring应用程序的类。配置类通常使用
@Configuration注解进行标记,表示该类是一个配置类。1
2
3
4
public class AppConfig {
// Bean定义
}@Bean
1
2
3
4
5
6
7
8
9
10
11
12
public class AppConfigWithLazy {
public MyBean myBean(){
System.out.println("myBean Initialized");
return new MyBean();
}
}每个Bean注解注释下的Bean方法也可以有参数,类似于
myBean(classA a)。详见自定义starter。源码跟踪
要搞清楚SpringBoot的自动配置原理,要从SpringBoot启动类上使用的核心注解@SpringBootApplication开始分析:
在@SpringBootApplication注解中包含了:
- 元注解(不再解释)
- @SpringBootConfiguration
@SpringBootConfiguration注解上使用了@Configuration,表明SpringBoot启动类就是一个配置类。
@Indexed注解,是用来加速应用启动的(不用关心)。
- @EnableAutoConfiguration
@EnableAutoConfiguration注解(自动配置核心注解):
一、使用@Import注解,导入了实现ImportSelector接口的实现类。
AutoConfigurationImportSelector类是ImportSelector接口的实现类。
二、AutoConfigurationImportSelector类中重写了ImportSelector接口的selectImports()方法:
三、selectImports()方法底层调用getAutoConfigurationEntry()方法,获取可自动配置的配置类信息集合
四、getAutoConfigurationEntry()方法通过调用getCandidateConfigurations(annotationMetadata, attributes)方法获取在配置文件中配置的所有自动配置类的集合。getCandidateConfigurations方法的功能:
获取所有基于META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件、META-INF/spring.factories文件中配置类的集合
- @ComponentScan
@ComponentScan注解是用来进行组件扫描的,扫描启动类所在的包及其子包下所有被@Component及其衍生注解声明的类。
SpringBoot启动类,之所以具备扫描包功能,就是因为包含了@ComponentScan注解。
总结!
自动配置原理源码入口就是@SpringBootApplication注解,在这个注解中封装了3个注解,分别是:
- @SpringBootConfiguration
- 声明当前类是一个配置类
- @ComponentScan 把当前包的Bean导入到IOC中
- 进行组件扫描(SpringBoot中默认扫描的是启动类所在的当前包及其子包)
- @EnableAutoConfiguration 把别的包中的Bean导入到IOC中。
- 封装了@Import注解(Import注解中指定了一个ImportSelector接口的实现类)
- 在实现类重写的selectImports()方法,读取当前项目下所有依赖jar包中META-INF/spring.factories、META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports两个文件里面定义的配置类(配置类中定义了@Bean注解标识的方法)。(
spring-boot-autoconfigure包内)
- 在实现类重写的selectImports()方法,读取当前项目下所有依赖jar包中META-INF/spring.factories、META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports两个文件里面定义的配置类(配置类中定义了@Bean注解标识的方法)。(
- 封装了@Import注解(Import注解中指定了一个ImportSelector接口的实现类)
@Conditional
按条件装配到IOC容器里面。
我们在跟踪SpringBoot自动配置的源码的时候,在自动配置类声明bean的时候,除了在方法上加了一个@Bean注解以外,还会经常用到一个注解,就是以Conditional开头的这一类的注解。以Conditional开头的这些注解都是条件装配的注解。下面我们就来介绍下条件装配注解。
@Conditional注解:
- 作用:按照一定的条件进行判断,在满足给定条件后才会注册对应的bean对象到Spring的IOC容器中。
- 位置:方法、类
- @Conditional本身是一个父注解,派生出大量的子注解:
- @ConditionalOnClass:判断环境中有对应字节码文件,如果有,才注册bean到IOC容器。
- @ConditionalOnMissingBean:判断环境中没有对应的bean(类型【value属性】或名称【name属性】),如果没有,才注册bean到IOC容器。
- @ConditionalOnProperty:判断配置文件中有对应属性和值,如果存在,才注册bean到IOC容器。(name和havingValue)
自定义starter
在自定义一个起步依赖starter的时候,按照规范需要定义两个模块:
- starter模块(进行依赖管理[把程序开发所需要的依赖都定义在starter起步依赖中])
- autoconfigure模块(自动配置)
将来在项目当中进行相关功能开发时,只需要引入一个起步依赖就可以了,因为它会将autoconfigure自动配置的依赖给传递下来。
AliOSSAutoConfiguration类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//当前类为Spring配置类
//导入AliOSSProperties类,并交给SpringIOC管理
public class AliOSSAutoConfiguration {
//创建AliOSSUtils对象,并交给SpringIOC容器
//可以在声明Bean的函数里面有参数,前提是这个参数对应的类必须也得是Bean(这个类由于不能加@Data所以要自己加get和set)
//声明Bean的方式有两种:
//1. 将这个Bean定义成ConfigurationProperties,然后在前面加上一句@EnableConfigurationProperties(Bean的名字.class),
public AliOSSUtils aliOSSUtils(AliOSSProperties aliOSSProperties){
AliOSSUtils aliOSSUtils = new AliOSSUtils();
aliOSSUtils.setAliOSSProperties(aliOSSProperties);
return aliOSSUtils;
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
public AliOSSProperties aliOSSProperties(){
return new AliOSSProperties();
}
// 2. 直接在这个配置类里面定义一个新的Bean即可。
public AliOSSUtils aliOSSUtils(AliOSSProperties aliOSSProperties){
AliOSSUtils aliOSSUtils = new AliOSSUtils();
aliOSSUtils.setAliOSSProperties(aliOSSProperties);
return aliOSSUtils;
}AliOSSProperties类:
1
2
3
4
5
6
7
8
9
10
11
12
13/*阿里云OSS相关配置*/
public class AliOSSProperties {
//区域
private String endpoint;
//身份ID
private String accessKeyId ;
//身份密钥
private String accessKeySecret ;
//存储空间
private String bucketName;
// get&set省略
}AliOSSUtils类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class AliOSSUtils {
private AliOSSProperties aliOSSProperties;
/**
* 实现上传图片到OSS
*/
public String upload(MultipartFile multipartFile) throws IOException {
// 获取上传的文件的输入流
InputStream inputStream = multipartFile.getInputStream();
// 避免文件覆盖
String originalFilename = multipartFile.getOriginalFilename();
String fileName = UUID.randomUUID().toString() + originalFilename.substring(originalFilename.lastIndexOf("."));
//上传文件到 OSS
OSS ossClient = new OSSClientBuilder().build(aliOSSProperties.getEndpoint(),
aliOSSProperties.getAccessKeyId(), aliOSSProperties.getAccessKeySecret());
ossClient.putObject(aliOSSProperties.getBucketName(), fileName, inputStream);
//文件访问路径
String url =aliOSSProperties.getEndpoint().split("//")[0] + "//" + aliOSSProperties.getBucketName() + "." + aliOSSProperties.getEndpoint().split("//")[1] + "/" + fileName;
// 关闭ossClient
ossClient.shutdown();
return url;// 把上传到oss的路径返回
}
}在aliyun-oss-spring-boot-autoconfigure模块中的resources下,新建自动配置文件:
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
1
com.aliyun.oss.AliOSSAutoConfiguration
这样子导入了configuration包之后,就可以把包中所有配置类(@Configuration)定义的Bean导入进去!这样子导入了configuration包之后,就可以把这个AliOSSUtils进行自动注入!