目标检测概论
目标检测,通俗点说就是给定一个图像,在图像中框出符合要求的区域。
用数学语言表达,就是:
训练集的输入是$(x_1,b_1),\dots,(x_n,b_n)$(其中$x_i$ 是原始$m*n$,k通道的图片,$b_i = {b_{i1},b_{i2},…,b_{ij},c_{i1},c_{i2},…,c_{ij}}$是若干个符合要求的区域$b_{ik}\in R^4$和它们的id$c_{ik}$),也就是说在神经网络的推理中,我们需要输入一个$x$得到一个$b$
R-CNN
传统目标检测方法包含预处理、窗口滑动、特征提取、特征选择、特征分类、后处理等步骤,而卷积神经网络本身具有特征提取、特征选择和特征分类的功能。那么,可以直接利用卷积神经网络对每个滑动窗口产生的候选区进行二分类,判断其是否为待检测目标。R-CNN因此而生。
R-CNN就是在CNN的基础上加了一层滑动窗口的选择。它有几点创新点:
- 确定了two stage网络的设计范式。two stage网络的基本思想是把网络拆分成分类(类别判断)和回归(位置判断)两个任务进行处理。
- 形成日后主流的目标检测模型范式:input(输入)、backbone(主干)、neck(转化)、head(预测)。
R-CNN的Input部分
这一部分是相较于CNN的关键区别,这一部分针对输入的图像,生成一系列可能有目标的识别框。对于每张输入的图片,采用Selective Search 方法,生成1K~2K个候选区域(region proposals/region of interest,Rol)。
首先先对图像做一次图像分割:这里使用Massachusetts Institute of Technology基于图计算的图像分割方法。首先建图$G(V,E)$。点集就是图像上的每一个像素。边集是相邻的像素集合。每条边上有一个非负的权重表示像素之间的相似度,图每条边的权值是基于像素点之间的关系,可以是像素点之间的灰度值差,也可以是像素点之间的距离。在图论中,图的分割是$S = (C_1,C_2,..,C_n) when C = G’(V’,E’) ,\sum V’ = V$,其中$V’$是$V$的一个子集,$E’$是$E$的一个子集,问题就转化成了求一个最优的图分割。本算法过程就相当于先将图分割成一个个顶点,然后通过合并策略,将它们合并,最后得到一个既不”太精细“也不”太粗糙“的分割。那是怎么进行合并的呢?论文中提出了一个叫做$MInt(C_1,C_2) = min(Int(C_1) + \tau(C_1),Int(C_2) + \tau(C_2))$的定义。这个定义基于$Int(C) = \max w(e)$(e是C中的边)。如果$MInt(C_1,C_2) > Dif(C_1,C_2)$,那么$C_1,C_2$就可以合并。(其中$Dif(C_1,C_2) = \min w(v_i,v_j)$,$v_i$和$v_j$是$C_1$和$C_2$中的点)。做多次合并,可以得到一个合理的图的分割。
原文地址:https://cs.brown.edu/people/pfelzens/papers/seg-ijcv.pdf)
得到了图的分割后,再对这个基础的分割进行一次聚类。根据之前计算好的$S$,计算S中每一个部分之间的相似度。在这里相似度可以表示成$s(r_i,r_j) = a_1s_{color}(r_i,r_j) + a_2s_{texture}(r_i,r_j)+ a_3s_{size}(r_i,r_j) + a_4s_{fill}$,其中每个相似度表示颜色相似度,纹理相似度,大小相似度和填充相似度。计算好相似度后对挑选相似度最高的两个区域进行合并。合并的方法是构建一个新的大框。
原文地址:https://ivi.fnwi.uva.nl/isis/publications/2013/UijlingsIJCV2013/UijlingsIJCV2013.pdf
R-CNN的BackBone部分
R-CNN使用了非常传统的AlexNet进行分析。
第1层输入层: 输入为224×224×3 三通道的图像。
第2层Conv层: 输入为224×224×3,经过96个kernel size为11×11×3的filter, stride = 4,卷积后得到shape为55×55×96的卷积层。
这里有2点值得注意的细节:(224-11)/4 + 1 = 54.25,
(1)按照论文中filter size和stride的设计,输入的图片尺寸应该为227×227×3。
(2)加上padding=2,则(224-11+2*2)/4 + 1 = 55.25,步长会略去小数,得到55.
第3层Max-pooling层: 输入为55×55×96,经Overlapping pooling(重叠池化)pool size = 3,stride = 2后得到尺寸为27×27×96 的池化层
第4层Conv层: 输入尺寸为27×27×96,经256个5×5×96的filter卷积,padding=same得到尺寸为27×27×256的卷积层。
第5层池化层: 输入为27×27×256,,经pool size = 3,stride = 2的重叠池化,得到尺寸为13×13×256的池化层。
第6~8层Conv层: 第6层输入为13×13×256,经384个3×3×256的filter卷积得到13×13×384的卷积层。 第7层输入为13×13×384,经384个3×3×384的filter卷积得到13×13×384的卷积层。 第8层输入为13×13×384,经256个3×3×384的filter卷积得到13×13×256的卷积层。 这里可见,这三层卷积层使用的kernel前两个维度都是3×3,只是通道维不同。
第9层Max-pooling层: 输入尺寸为13×13×256,经pool size = 3,stride = 2的重叠池化得到尺寸为6×6×256的池化层。该层后面还隐藏了flatten操作,通过展平得到6×6×256=9216个参数后与之后的全连接层相连。
第10~12层Dense(全连接)层: 第10~12层神经元个数分别为4096,4096,1000。其中前两层在使用relu后还使用了Dropout对神经元随机失活,最后一层全连接层用softmax输出1000个分类。(分类数量根据具体应用的数量变化,比如数据集中有10个类别,则最后输出10)
R-CNN的Head部分
R-CNN使用一个SVM分类器来判别图片的类别(一个one-hot向量),使用一个回归器来预测目标的位置坐标(一个坐标四元组)。到了最终的预测结果输出阶段,还需要使用非极大值抑制(NMS)算法去除多余的候选区域。非极大值抑制(Non-maximal suppression,NMS)合并相似的预测。原来的NMS是用于锚框的情况,这里用于网格的情况。先从所有锚框中选取一个置信度高的锚框并对其进行标记,然后去掉(抑制)与其IOU值大于$\epsilon$的锚框;重复上面步骤,直至所有的锚框都被标记。
SPPNet(Spatial Pyramid Pooling Networks)
卷积神经网络的全连接层需要固定输入的尺寸,而Selective search所得到的候选区域存在尺寸上的差异,无法直接输入到卷积神经网络中实现区域的特征提取,因此RCNN先将候选区缩放至指定大小随后再输入到模型中进行特征提取。
RCNN使用Selective Search从图像中获取候选区域,然后依次将候选区域输入到卷积神经网络中进行图像特征提取,如果有2000个候选区域,则需要进行2000次独立的特征提取过程。然后,这2000个候选区域是存在一定程度的重叠的,所以如此设计会导致大量的冗余计算。
SPP-Net究竟做了什么呢?CNN网络需要固定尺寸的图像输入,SPPNet将任意大小的图像池化生成固定长度的图像表示。SPPNet在最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定。
其次呢,SPPNet先做一次卷积,在卷积好的图像中进行Selective Search。由于做卷积操作不影响图像的位置,所以这样做是没问题的。
原文地址:http://arxiv.org/pdf/1406.4729
Fast R-CNN
Fast R-CNN最重要的改进就是利用SPPNet,与R-CNN一样,利用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
但是,Fast R-CNN与R-CNN不同的是,这些生成出来的候选区域不需要每一个都丢到卷积神经网络里面提取特征,而且只需要在特征图上映射便可。
这样做的好处就是对于每一个框出来的区间,不需要都做一次卷积操作,而是直接可以进行池化和全连接了。在这里所有的图像都会池化成$7 \times 7$的特征矩阵。最后全连接层中有一个概率分配器和位置回归器。和R-CNN同理。Loss函数也分成分类loss(一般来说就是引入一个softmax层做交叉熵)和回归loss(smooth-L1损失)两部分
$$L(p,u,t^u,v) = L_{cls}(p,u)+\lambda u(u<1)L_{rgs}(t^u,v)$$

Faster R-CNN
相较于Fast R-CNN,做的优化就是引入了区域建议网络(Region Proposal Network,RPN)代替Selective Search算法。其核心思想就是利用锚点进行运算。
原文地址:https://arxiv.org/pdf/1504.08083
Yolo
Yolo是You only look once的简写。采用单阶段网络(one-stage)。预测(物体位置和类别)由一个网络进行。可以进行端到端(end-to-end)训练以提高准确性。所以叫Look Once()
YOLO将输入的图片resize成448 x 448,并且为 S x S(S = 7)个grid,如果物体的中心落入该grid中,那么该grid就需要负责检测该物体。一次性输出所检测到的目标信息,包括类别和位置。综上,S×S 个网格,每个网格要预测 B个bounding box ,还要预测 C 个类。网络输出就是一个 S × S × (5×B+C)。(S x S个网格,每个网格都有B个预测框,每个框又有5个参数,再加上每个网格都有C个预测类)
YOLOv1采用的是“分而治之”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。回忆一下,在Faster R-CNN中,是通过一个RPN来获得目标的感兴趣区域,这种方法精度高,但是需要额外再训练一个RPN网络,这无疑增加了训练的负担。在YOLOv1中,通过划分得到了7×7个网格,这49个网格就相当于是目标的感兴趣区域。通过这种方式,我们就不需要再额外设计一个RPN网络,这正是YOLOv1作为单阶段网络的简单快捷之处!
在Yolov1中是7 × 7 × 30(30等于两个框的xywh和置信度+所属类别的概率【20个】)。YOLO 有 24 个卷积层,后面是 2 个全连接层(FC)。一些卷积层交替使用 1×1 减少层来减少特征图的深度。在网络中,我们规定损失函数由分类预测损失、坐标预测损失(预测的bounding box和ground truth之间的差距)和置信度预测损失(框的客观真实性)组成,具体的损失函数的表示不表。
Yolov5
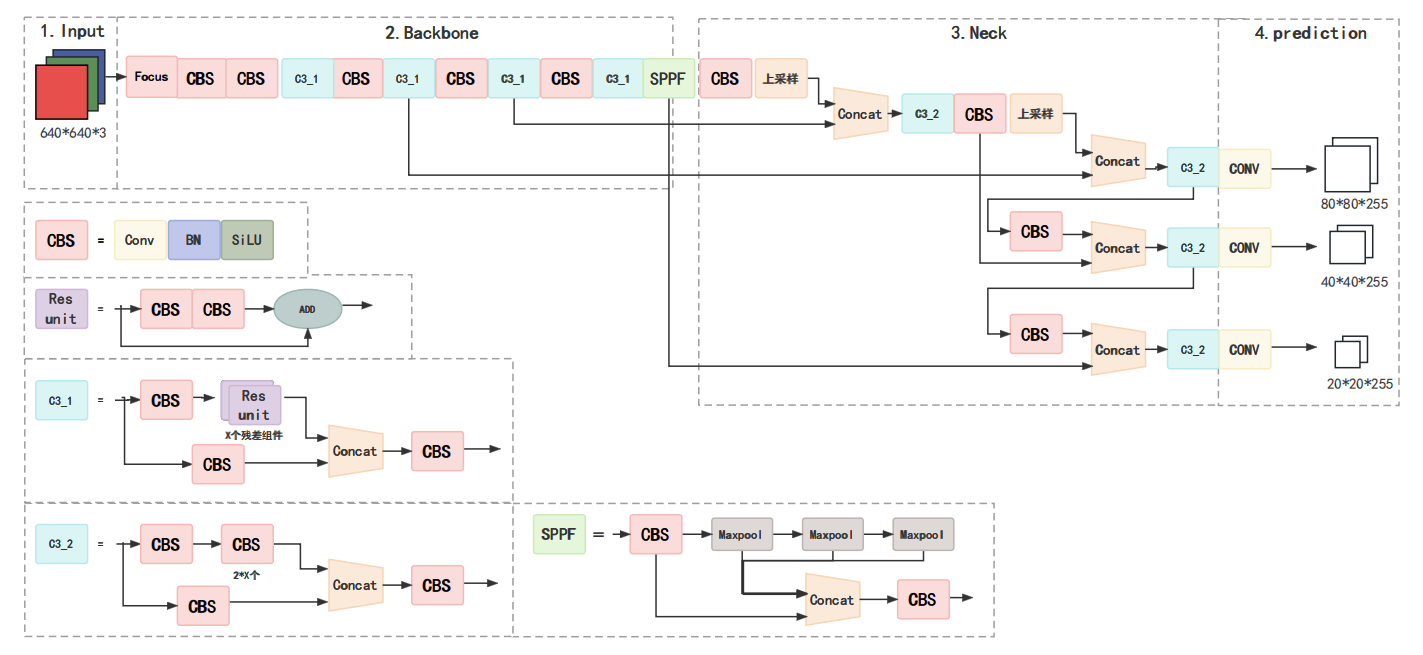
Yolo是基于R-CNN的一种神经网络框架,如图所示: